

“Cerca di anticipare i piani del nemico, e individua i suoi punti forti e deboli: potrai decidere quale strategia usare per avere successo, e quale no.”
Una delle fasi fondamentali in un attacco è la sua preparazione. Più accurata ed esaustiva è l’analisi sull’obbiettivo, più efficace sarà la nostra preparazione, la stesura della nostra strategia e di conseguenza le nostre probabilità di successo.
Lo scopo della fase di ricognizione è attingere al maggior numero di informazioni utili sul target da utilizzare nella fase d’attacco, non lasciando che la nostra vittima si accorga di cosa sta avvenendo. Per raggiungere il nostro obbiettivo effettueremo la nostra ricognizione servendoci di tecniche di Investigazione su fonti pubbliche/aperte: Open-source intelligence (OSINT).
Che cosa è l’OSINT?
Potremmo definire l’OSINT come: “la scansione, la ricerca, la raccolta, l’estrazione, l’utilizzo, la convalida, l’analisi e la condivisione delle informazioni pubbliche/aperte disponibili da fonti non classificate e non segrete”. Un vero e proprio percorso di investigazione fra i dedali della rete, cercando tasselli di bit per una visione macro (e a volte anche micro) del nostro target, sia esso una grande azienda oppure un singolo soggetto.
Perché la fase di ricognizione è fondamentale?
Tutte le informazioni che riusciremo a reperire durante il nostro percorso investigativo ci aiuteranno sia a comprendere quale è l’anello debole da attaccare sia quale tipologia di attacco portare.
Ad esempio:
- se dovessimo avvalerci di tecniche di phishing avremmo bisogno di identificare quali utenti siano più vulnerabili.
- Nel caso dovessimo eseguire un “Password Guessing Attack” avremmo bisogno di scoprire quale sia il corretto formato che la data azienda utilizza per creare lo username dei propri utenti.
- Informazioni sull’infrastruttura possono aiutarci a capire quale sistema AV/EDR è in uso e quindi quali tecniche di evasion utilizzare affinché il nostro payload non venga rilevato.
- Potremmo apprendere informazioni sulla topologia di rete o dati architetturali che ci aiuterebbero nella fase di pivoting all’interno della rete.
- Numeri di telefono ed e-mail, utilizzabili per mettere in atto tecniche di Social Engineering, fingendoci qualcuno del reparto IT oppure un utente che contatta l’Help Desk perché non riesce più ad accedere al proprio computer.
- Potremmo addirittura reperire alcune credenziali utili da DataBreach vecchi e se l’utente o la password non sono più in uso, avremo comunque capito quali sono le regole applicate dall’azienda per la costruzione di nomi utente e password.
Tipologia di Dati
I dati utili al nostro scopo che potremmo reperire, di un dato utente o di un’organizzazione, potrebbero essere stati condivisi in maniera Intenzionale o non Intenzionale.
Dati pubblicati Intenzionali
- URLs e Websites
- Nomi di progetti
- Report annuali sull’andamento
- Offerte di lavoro
Dati non intenzionalmente pubblicati/esposti
- Informazioni sugli account ottenute da breach di terze parti
- Social Media del nostro Target (sia esso un privato o un dipendente)
- Metadati
- Server Banner
Vediamo adesso quali fonti, tool e posti potremmo dover visitare o utilizzare durante la nostra caccia alle informazioni.
Supponiamo che il nostro target sia una grande azienda.
WIKIPEDIA
Un semplice quanto banale punto di partenza potrebbe essere consultare Wikipedia (se l’organizzazione da attaccare o il dato soggetto è grande/famoso abbastanza). Potremmo reperire alcune informazioni di basilari sulla sua storia che non sempre sono presenti sul sito Web. Trovare sub-companies o affiliati che potrebbero avere accesso indirettamente all’organizzazione, o semplicemente potrebbero essere più vulnerabili al Phishing.
POSIZIONI DI LAVORO APERTE
Moltissime organizzazioni hanno posizioni aperte sul loro sito internet. Questo potrebbe aiutarci a capire quali informazioni, tecnologie o prodotti in uso sul nostro target:
- Tipologia del Web Server
- Tipologie di Firewall
- Routers
- Ambienti utilizzati dagli sviluppatori
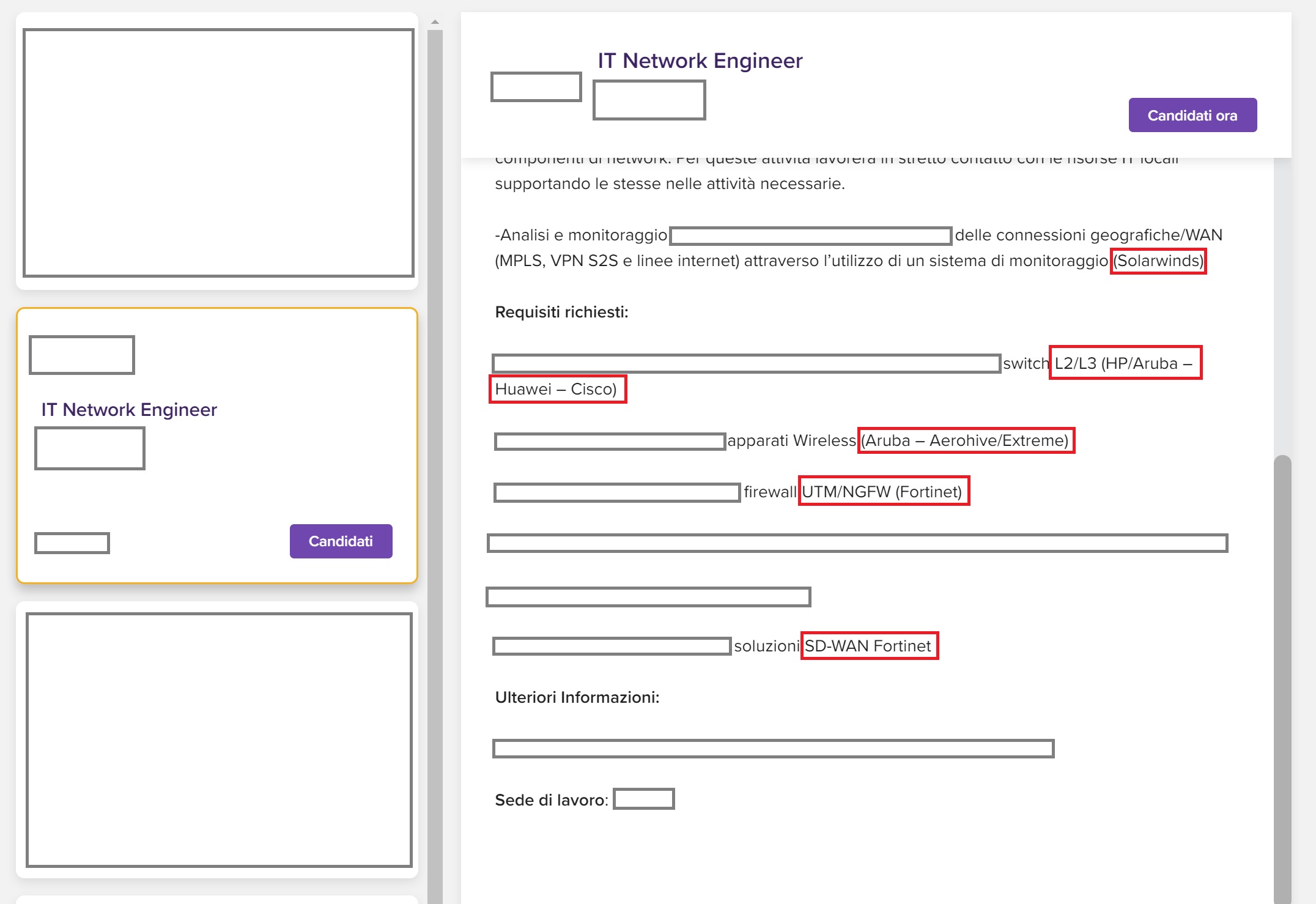
Ad esempio, potremmo decidere di cercare su https://www.monster.it/ la parola “Sistemista” e la zona geografica.
WHOIS
Il Whois è un protocollo di rete che permette di associare il provider con un dato DNS o indirizzo IP. Nelle informazioni contenute, spesso vengono rilevati anche i dati dell’intestatario.
Eseguiamo ad esempio il Whois sul nostro blog: thehakingquest.net
whois thehakingquest.net --verbose
- whois : comando
- net : dominio target
- –verbose : opzione di visualizzazione dell’output verbose
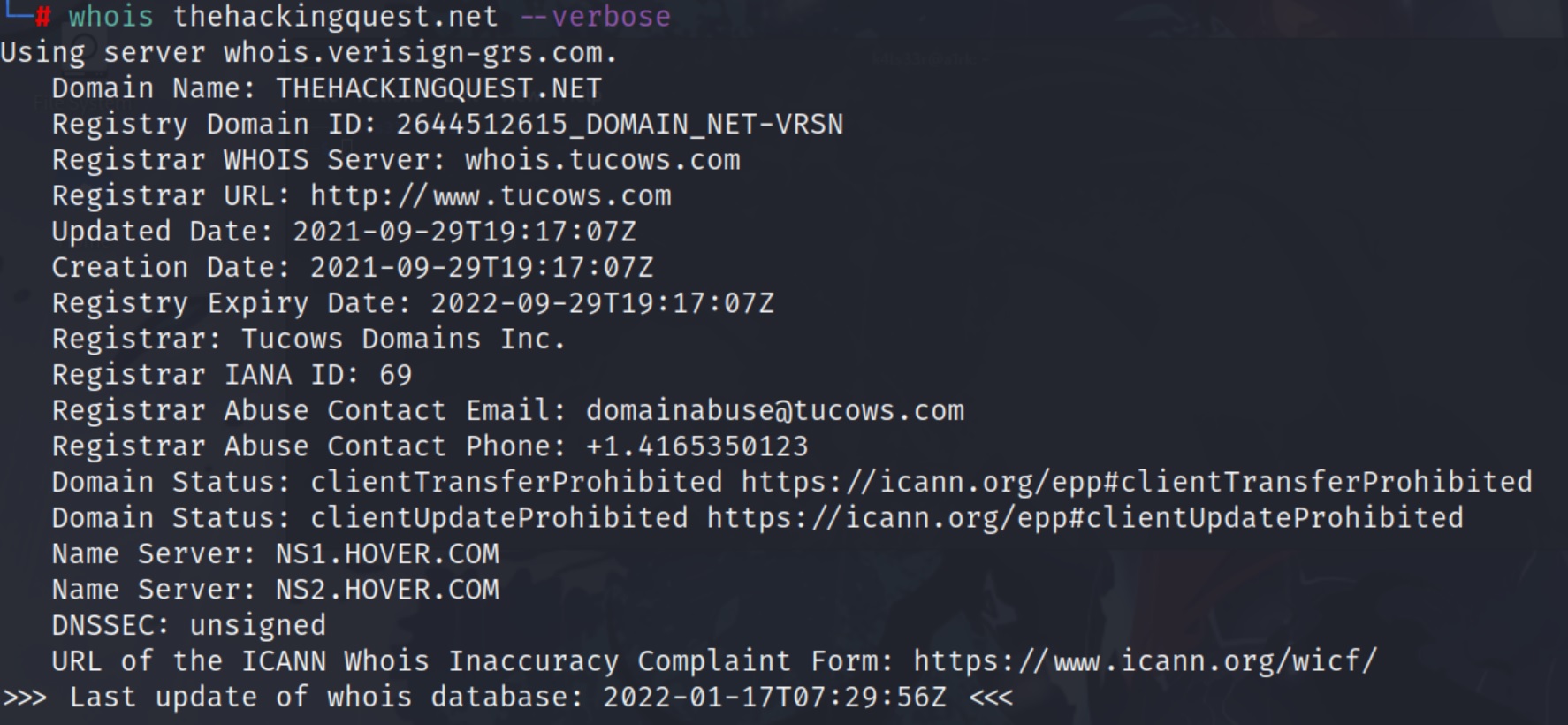
Gli elementi finali dell’interrogazione secondo query whois rilevano le informazioni relative al Domain Name System (DNS) associati al target. Nel prossimo paragrafo, proveremo ad attingere informazioni dai records del name servers.

DNS SERVERs
Lo scopo primario del DNS è risolvere i nomi di dominio in indirizzi IP, ma non è il solo. Essi svelano anche altre informazioni utili, tra cui fornire indicazioni su quali macchine siano i mail-server per il dato dominio. Esistono infatti diversi tipi di record:
- NS: Il Nameserver record indica il nome dei server associati al dominio target
- A: Address record, mappa il domain name nell’indirizzo IPv4 corrispondente
- AAAA: “Quad-A” record, mappa il domain name nell’indirizzo IPv6 corrispondente
- HINFO: Host Information Record, associa informazioni arbitrarie con il nome di dominio (solitamente viene usato per indicare la tipologia del sistema)
- MX: Mail Exchange record, identifica i server mail per il dato dominio
- TXT: Text Record, include una stringa di testo per il dominio
- CNAME: Canonical Name, indica un alias o un nome alternativo per il dominio
- SOA: Start of Authority record, marca il server come “Autorevole” per la DNS Zone
- RP: Responsible Person Records, record informative e non funzionale che indica l’incaricato o la persona responsabile per il dato dominio
- PTR: Reverse Record, indica l’indirizzo IP per il dato server
- SRV: Service location records, fornisce informazioni incluso porta e hostname dei servizi disponibili
Supponiamo adesso di voler eseguire delle query sui DNS name servers, utilizzando il comando Domain Information Groper (dig). Digitiamo il comando:
dig thehackingquest.net
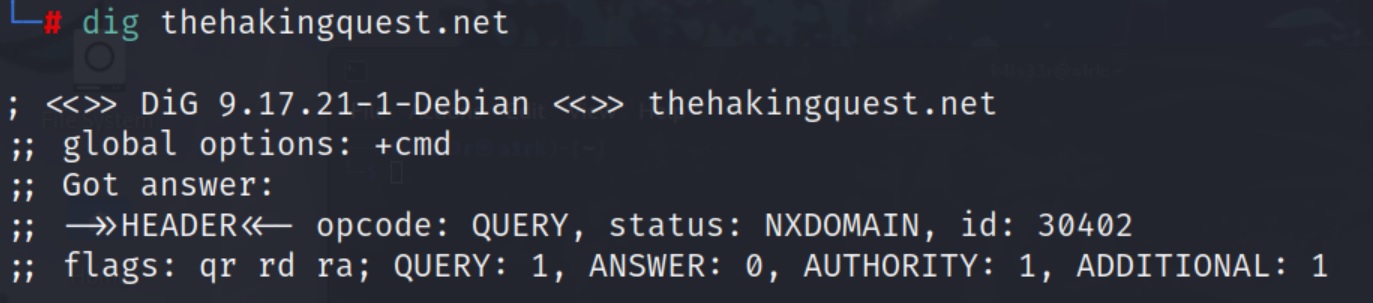
Esiste un processo chiamato “Zone Transfer” per cui un server DNS passa una copia del suo database (chiamato “zona”) ad un altro server DNS. L’attacco chiamato “Zone Transfer Attack” consiste nel chiedere al DNS primario una copia dei record di zona. L’attacco si basa sull’assunto che tutti i server sono “trusted” gli uni con gli altri. Per eseguire questo attacco utilizzando il tool dig dovremo dare il seguente comando:
dig @[server] [dominio] -t AXFR
- dig : comando
- @[server] : DNS server
- [dominio] : nome del dominio
- -t : specifica la tipologia della query
- AXFR : richiede la copia della DNS Zone
Esistono anche altri tool che permettono di automatizzare le query ai DNS servers. Ad esempio, DNSrecon permette di eseguire anche attacchi bruteforce con una dictionary list.
dnsrecon -d [dominio] -t brt -D [wordlist]
oppure:
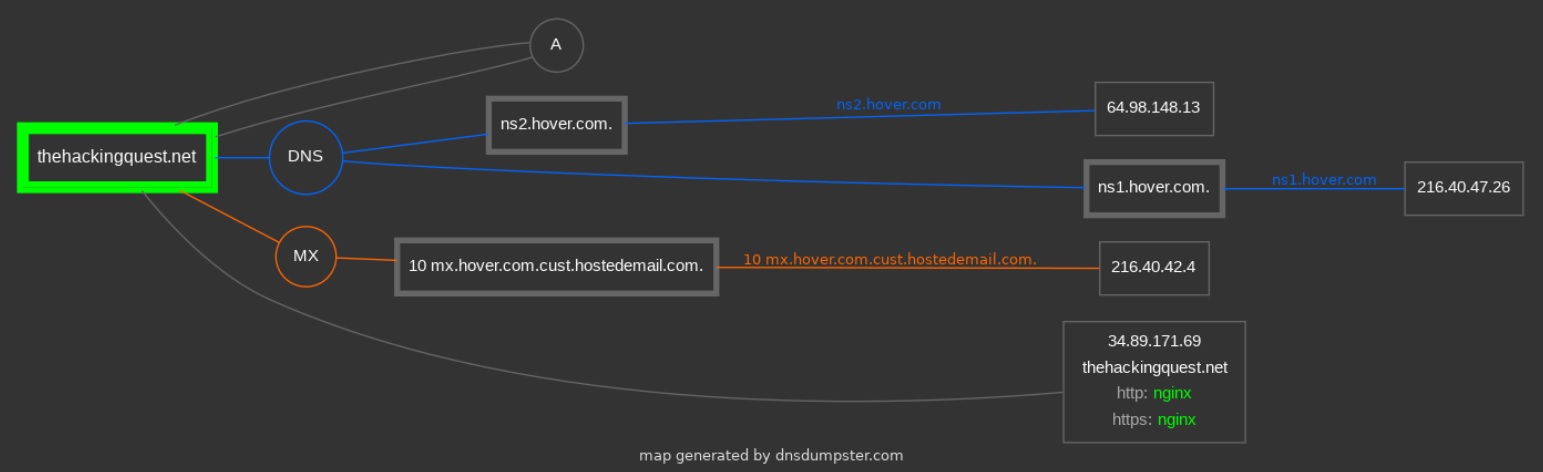
DNSDumpster: https://dnsdumpster.com/
La versione free ci fornisce più di un centinaio di DNS A record, con i corrispondenti Indirizzi IP e i relativi Autonomous System Number (ASNs). Un AS è un insieme di IP appartenenti ad una rete o ad un insieme di reti, gestite, controllate e supervisionate da una singola entità o organizzazione.
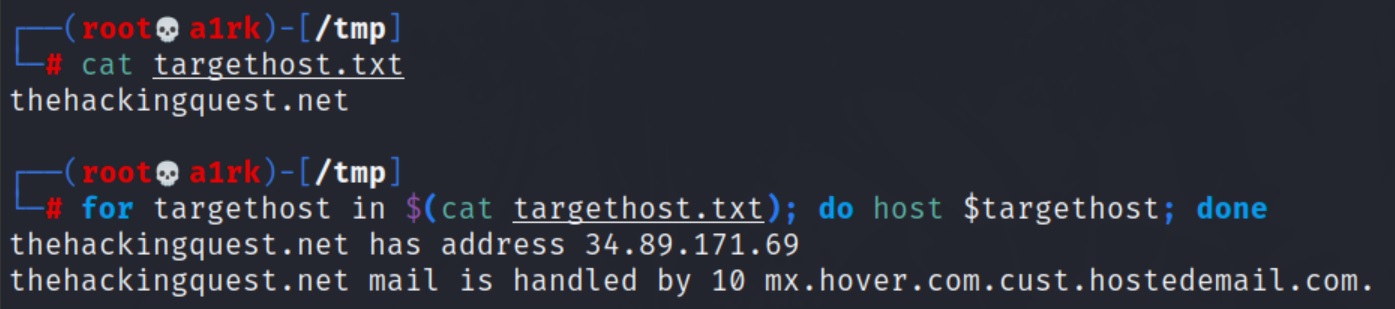
Diversamente, potremmo scrivere in autonomia il nostro script: supponiamo di avere appena formulato una lista di potenziali nomi host che la nostra organizzazione target espone pubblicamente sulla rete e di aver chiamato il file targethost.txt (nomedelserver.nomeorganizzazione.com)
Per il nostro scopo utilizzeremo il comando host, che ci permetterà di interrogare il DNS al fine di identificare quale indirizzo IP si cela dietro un dato hostname (ovviamente se il nome non esiste, non verrà fornito nessun IP).
Quindi scriviamo il nostro comando:
for targethost in $(cat targethost.txt); do host $targethost; done
Se l’hostname esiste, il nostro script ci fornirà il suo indirizzo IP.
WHOIS DATABASE
Un altro elemento importante per poter ampliare la superficie del nostro attacco, consiste nell’identificare il blocco di IP pubblici assegnati alla nostra società bersaglio.
Diverse regioni offrono il database whois contenente le informazioni degli IP relativi ad uno specifico dominio. Vediamo quali sono le principali:
- ARIN : American Registry for Internet Numbers
- RIPE NCC : The Réseaux IP Européens Network Coordination Centre
- APNIC : The Latin American and Caribbean Internet Address Registry
- AS : Autonomous System
Ovviamente, non tutte le organizzazioni hanno un blocco di IP a loro designato, ma a molte viene assegnato un indirizzo IP pubblico dal loro Internet Service Provide (ISP).
SHODAN
Shodan è un search engine che costantemente effettua scansioni su internet al fine di mappare gli hosts connessi e raccogliere informazioni su porte e servizi in ascolto, come certificati SSL (che possono rivelare altri sotto domini, Geolocalizzazione degli IP, etc…).
Facciamo un breve esempio: supponiamo che io voglia cercare con shodan tutte le webcam, scegliendo di visualizzarne solamente IP, porta, organizzazione e hostname.
Come prima cosa, dobbiamo inserire la nostra API Key (reperibile anche senza registrazione sulla rete). Apriamo un terminale sulla nostra macchina attaccante e digitiamo:
shodan init [La nostra API Key]
Una volta che la sincronizzazione sarà avvenuta decidiamo cosa cercare, ad esempio le webcam, e digitiamo:
shodan search --fields ip_str,port,org,hostnames webcam
BUILTWITH
BuiltWith è un utile strumento che ci può dare una lista di tutte le tecnologie in uso per un determinato dominio e sotto dominio:
- Web Host
- Web Server
- Detected CDN
- Frameworks
- Widgets
HOSTNAME INFORMATIONS
È bene tenere presente che il nome della macchina molte volte indica anche il suo scopo. Per il password spraying attack è utile verificare l’esistenza delle seguenti macchine:
- Nomi che contengono login, portal, sso, adfs o remote
- Online email: mail, autodiscover, owa
- Citrix: ctx, citrix storefront
- VPN: vpn, access
SERACH ENGINE
La tecnica è anche nota come Dorking o Google Hacking ed è una tecnica utilizzata per effettuare interrogazioni sul web sfruttando il motore di ricerca Google.
Esiste un database di riferimento con cui sbizzarrirsi: https://www.exploit-db.com/google-hacking-database. Vediamo le basi:
- site: consente all’attaccante di cercare in un singolo sito o dominio.
- intitle: cerca i criteri specificati nella page-title
- inurl: cerca nell’URL specificato
Possiamo inoltre specificare l’estensione di ciò che cerchiamo (.pdf , .docx , .xlsx, etc…). Quindi ad esempio, se vogliamo cercare tutti i documenti pdf contenuti nel sito microsoft .com, inseriremo nella barra di ricerca di google il seguente comando:
site: microsoft.com filetype:pdf
Altri esempi di Dorks potrebbero essere:
site:example.net ext:xml | ext:conf | ext:cnf | ext:reg | ext:inf | ext:rdp | ext:cfg | ext:txt | ext:ora | ext:ini
Dove “site” è il sito target ed “ext” sta per “estensione”. Ergo, nei tre siti registrati a nome della holding Example S.p.A verranno ricercati eventuali file di configurazione esposti.
Al fine di cercare le pagine di Login in correlazione con il target, possiamo digitare:
site:example.net inurl:login
DOCUMENT METADATA
Solitamente, quando viene creato un documento utilizzando un determinato software, questo porta con sé numerose informazioni che non sempre vengono eliminate, quali ad esempio:
- Usernames
- File system paths
- Email address
- Client-side software use
- Altre informazioni
Ci sono molti tool impiegati per estrarre metadati, i più comuni sono:
- PowerMeta : https://github.com/dafthack/PowerMeta
- ExifTool
- FOCA: https://github.com/ElevenPaths/FOCA
- Metadata Extraction : https://github.com/DIA-NZ/Metadata-Extraction-Tool/
NOTA
È un sito che esegue regolarmente profilazioni OSINT di aziende
- Fornisce i pattern comuni di e-mail
- È un servizio a pagamento
PUBLIC BREACHDATA CREDENTIAL
I data breach sono una fonte inesauribile di risorse e anche quando username o password sono state cambiate, possono fornire comunque informazioni sulle regole di creazione utilizzate dall’azienda target.
Dove possiamo reperire i DataBreach?
- HaveIBeenPwned.com
- Dehashed.com
- Scylla.so
- Dump su forum pubblici
- Torrents
- Altro, come ad esempio: Archive.org
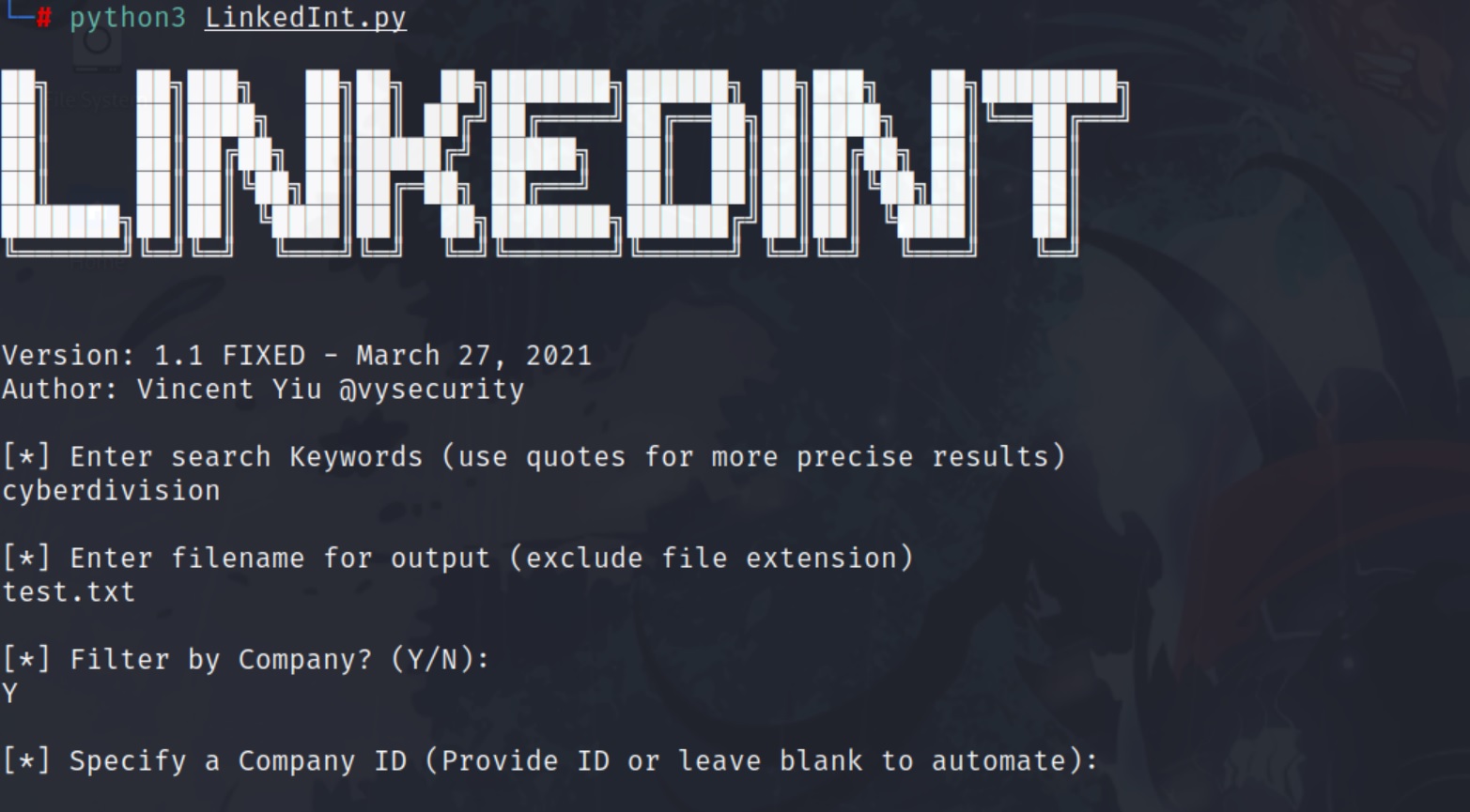
SOCIAL – LinkedIn
LinkedIn è un’ottima piattaforma per fare ricognizione ai danni di una data organizzazione. Offre infatti l’opportunità di profilare i dipendenti, ottenendo: nomi, titoli, indirizzi email, affiliati, etc…
Un buon tool per raccogliere informazioni sui dipendenti nomi/indirizzi email è LinkedInt scaricabile al seguente indirizzo: https://github.com/vysecurity/LinkedInt
Oppure, possiamo scegliere di utilizzare un’estensione di Burp Suite chiamata GatherContacts, scaricabile al seguente link: https://github.com/clr2of8/GatherContacts
SPIDERFOOT
SpiderFoot è un OSINT scanner automatico che utilizza più di cento moduli differenti.
Vediamo come utilizzarlo per fare la nostra ricerca. Come prima cosa, al fine di scaricare l’ultima release disponibile, apriamo sulla macchina attaccante un nuovo terminale e digitiamo:
wget https://github.com/smicallef/spiderfoot/archive/v3.5.tar.gz
Estraiamo il contenuto del file .gz
tar zxvf v3.5.tar.gz
Entriamo nella directory così creata: cd spiderfoot-3.5
Installiamo i requisiti necessari:
pip3 install -r requirements.txt
Ed infine avviamo il nostro tool in locale sulla porta 5001:
python3 ./sf.py -l 127.0.0.1:5001
Da un altro terminale apriamo il nostro browser (nel mio caso Firefox):
firefox –private
Sulla barra degli indirizzi digitiamo:
A questo punto, dovrebbe esserci apparsa la pagina di SpiderFoot. Clicchiamo su “New Scan” in alto a sinistra.
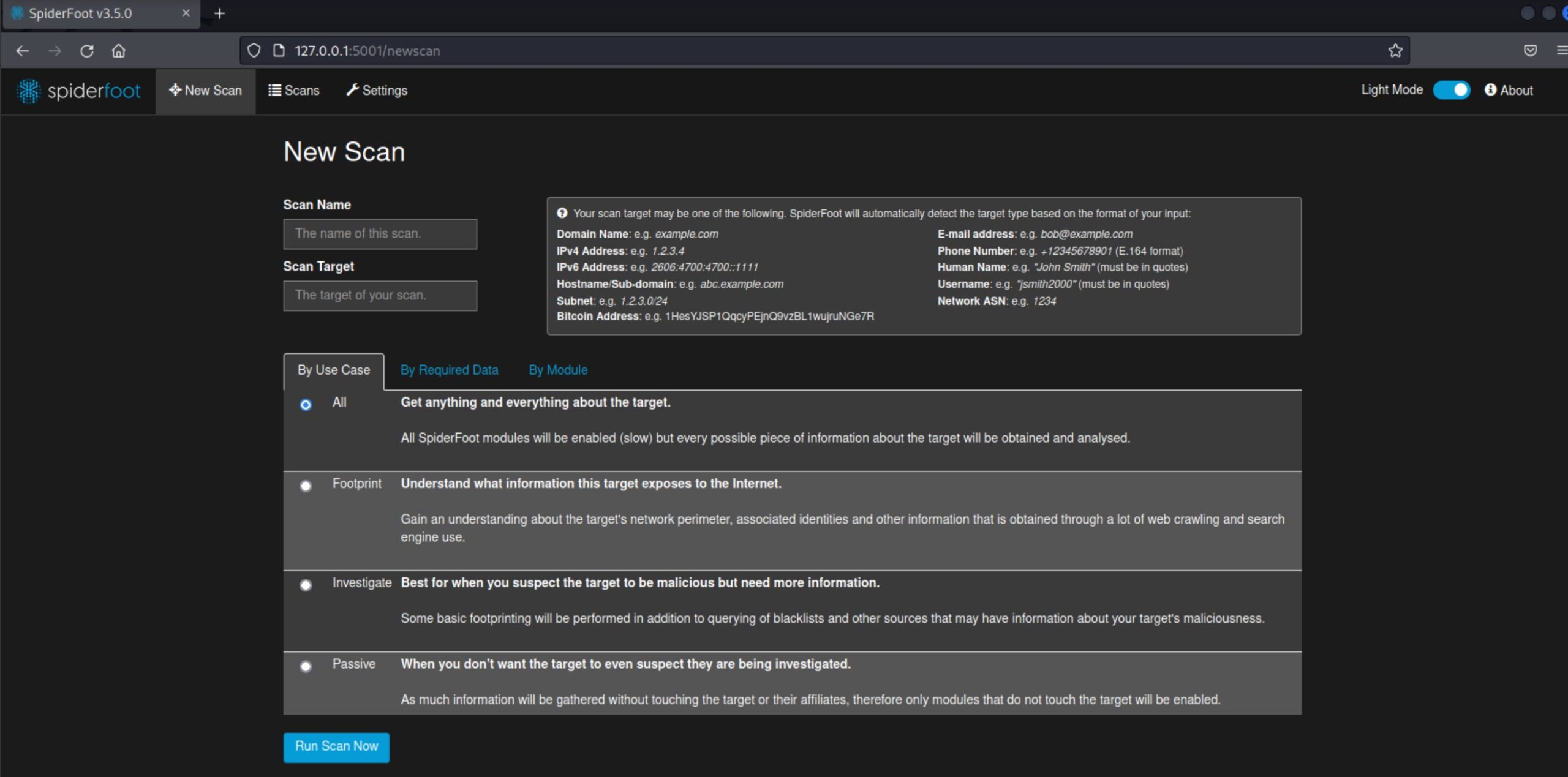
Scegliamo una delle quattro opzioni:
- All : utilizza tutti i moduli disponibili, ma impiega molto tempo (giorni)
- Footprint : esegue la scansione circoscritta al perimetro della rete (per la maggior parte sono risultati derivanti da search engine e web crawling)
- Investigate : utile soprattutto ai Blue Team, in quanto designata ad analizzare potenziali siti ed IP malevoli o sospetti
- Passive : nessuna query diretta al target o ad affiliati, puro OSINT
Infine, inseriamo nella maschera a sinistra Nome e Target. Ci vorrà del tempo a seconda dell’opzione che abbiamo selezionato, ma alla fine otterremo il nostro risultato:
DUMPSTERDIVING
Esistono altre tecniche “rudimentali”, ma non meno efficaci, utilizzate per carpire informazioni potenzialmente utili. Ad esempio, la ricerca di informazioni là dove la vittima cestina i suoi rifiuti.


