

Che cosa sono i DeepFake
[ torna al menu ]
Il termine deepfakes è un costrutto che deriva dai termini “apprendimento profondo” e “falso”. È una tecnica che sfrutta l’intelligenza artificiale al fine di manipolare i volti di due persone, sovrapponendo l’immagine del viso di un dato soggetto (il bersaglio) con quella di un altro individuo presente in un video.
La tecnica è conosciuta anche come face swapping ed ha come risultato la generazione di un video fake quasi indistinguibile da uno autentico.
Esistono due sotto categorie nell’ambito del face swapping:
- Lip-sync : tecnica di deepfaking che modifica i video al fine di renderli coerenti con l’audio di registrazione.
- Puppet-Master: tecnica che si compone di una vittima, il “puppet”, che viene animata con espressioni facciali, movimenti oculari e della testa appartenenti al “master”, seduto davanti alla telecamera.
Tali metodi di deepfake richiedono normalmente un’ingente quantità di dati ed immagini video per addestrare l’Intelligenza Artificiale a creare modelli per immagini e video realistici. È questo il motivo per cui, ad esempio, celebrità e politici con un elevato numero di video e immagini disponibili online, rappresentano un facile bersaglio.
Il primo deepfake emerse nel 2017 e per la prima volta il viso di una celebrità venne sostituito al viso di un’attrice porno. Ma fu solo successivamente, quando il face swapping fu applicato a personalità politiche e leader mondiali, creando tensioni religiose e politiche tra Paesi, che emerse il lato più oscuro della loro minaccia.
Questi tool, infatti, possono essere utilizzati per generare immagini satellitari false, contenenti oggetti inesistenti, allo scopo di confondere gli analisti militari. Ad esempio, basti pensare che l’inserimento di un passaggio dove in realtà non esiste, potrebbe causare un’erronea pianificazione di un piano di battaglia.
Creazione
[ torna al menu ]
I deepfake sono divenuti popolari grazie alla qualità dei video che riescono a generare e alla loro facilità di utilizzo. Generalmente tutti i tool per il face swap sono sviluppati con tecniche di Deep Learning. Il Deep Learning (letteralmente “apprendimento profondo”) è una branca dell’Intelligenza Artificiale che fa riferimento alle reti neurali artificiali, cioè a tutti quegli algoritmi ispirati alla struttura e alle funzioni del cervello. In altre parole, il Deep Learning è tutto ciò che le “macchine” riescono ad apprendere attraverso i dati forniti da algoritmi.
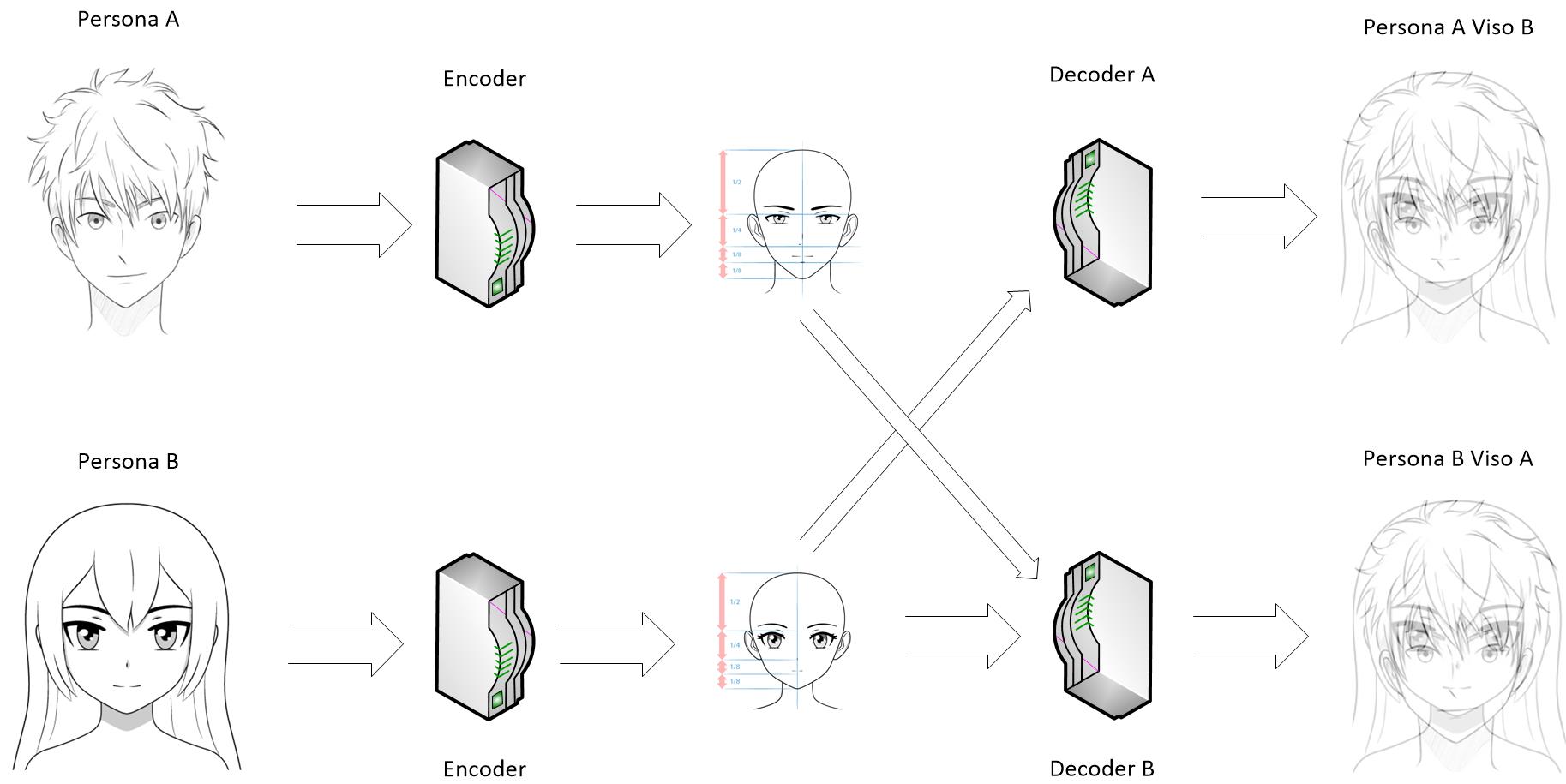
Prendiamo come esempio FakeApp, sviluppata da un utente di Reddit. Essa utilizza un auto-encoder-decoder per l’associazione delle due immagini: l’auto-encoder estrae le caratteristiche da un volto; il decoder si occupa invece di ricostruire l’immagine del volto. Per “swappare” i volti vengono utilizzate due coppie di encoder-decoder. Questa strategia permette agli encoder in comune di imparare le somiglianze fra i due set di volti.
Di seguito, trovate una lista di diversi tool per il deep fake.
- Faceswap https://github.com/deepfakes/faceswap
- Faceswap-GAN https://github.com/shaoanlu/faceswap-GAN
- Few-Shot Face Translation https://github.com/shaoanlu/fewshot-facetranslation-GAN
- DeepFaceLab https://github.com/iperov/DeepFaceLab
- DFaker https://github.com/dfaker/df
- DeepFake tf https://github.com/StromWine/DeepFake
- AvatarMe https://github.com/lattas/AvatarMe
- MarioNETte https://hyperconnect.github.io/MarioNETte
- DiscoFaceGAN https://github.com/microsoft/DiscoFaceGAN
- StyleRig https://gvv.mpi-inf.mpg.de/projects/StyleRig
- FaceShifter https://lingzhili.com/FaceShifterPage
- FSGAN https://github.com/YuvalNirkin/fsgan
- Transformable Bottleneck Networks https://github.com/kyleolsz/TB-Networks
- “Do as I Do” Motion Transfer https://github.com/carolineec/EverybodyDanceNow
- Neural Voice Puppetry https://justusthies.github.io/posts/neuralvoice-puppetry
Tecniche e metodi per riconoscere i DeepFake:
[ torna al menu ]
Ad una prima analisi, potremmo porci il problema dei deepfake come un problema binario: è un fake o non lo è? Tale approccio richiede un ampio database contenente video reali e video fake, al fine di addestrare un modello di classificazione che verrà successivamente utilizzato per determinare se un video o un’immagine siano vere oppure no. Ma dato il numero limitato di data-set a disposizione, è necessario ricorrere a metodi migliori per il rilevamento di un deepfake.
In realtà, dobbiamo scorporare il problema in sottocategorie: il rilevamento di immagini fake e i metodi di rilevamento di video fake. A loro volta questi elementi sono scorporabili in sottocategorie “visual artifacts”, basate su metodi di scorporazione dei frame del video e caratteristiche temporali (che utilizzando il deep learning).
L’immagine successiva mostra la convoluzione: la curva di colore verde delle curve blu e rosse in funzione di t (l’immagine è statica ma dovreste immaginarla in scorrimento). Convoluzione significa letteralmente “far scorrere mescolando assieme due artefatti”. Matematicamente si intendono due funzioni “mescolate” assieme, che generano una terza funzione che rappresenterà il prodotto (la convoluzione) delle due funzioni.

Tecniche
[ torna al menu ]
Ma, per comprendere le varie tecniche di detection, dobbiamo prima imparare alcune tecniche di apprendimento automatico:
Rete Neurale convoluzionale (CNN o ConvNet) : vengono utilizzate nel campo del Deep Learning, per il riconoscimento di immagini ed estrazioni di determinate caratteristiche da una “rete” già precedentemente addestrata, in modo da utilizzarla per addestrarne altre. Si può effettuare il train di una CNN su CPU, singola GPU, GPU multiple in parallelo.
Rete convoluzionale ricorrente a lungo termine (LRCN): si identificano tramite CNN caratteristiche visive per generare una pila di modelli costituita da sequenze ricorrenti.
Long Short Term Memory (LSTM): ha una struttura a catena che permette di propagare una data informazione in un lasso di tempo più lungo, in modo da decidere nel corso della computazione quali informazioni lasciare andare e quali mantenere durante il tutto il processo.
VGG-19: è una rete convoluzionale basata su 19 livelli di profondità.
Support Vector Machine (SVM): è basato sull’idea di trovare un iperpiano che divida al meglio un set di dati in due classi, cioè un limite di “decisione” che separi i valori di una classe dall’altra. In altri termini, un “confine” dove determinati dati vengono disgiunti dagli altri.
Photo Response Non-Uniformity (PRNU): il PRNU descrive il rapporto tra la potenza ottica su un pixel, rispetto all’uscita del segnale elettrico. Il valore ci informa della variazione dei pixel in una condizione di pari attraversamento di luce. Viene utilizzato per Identificare la Sorgente di una Fotocamera (SCI) in modo da affermare con certezza che un determinato contenuto digitale, ad esempio un video, sia stato catturato da una data fotocamera appartenente ad un dato device.
Attribution-Based Confidence (ABC): la metrica ABC è una tecnica che non richiede addestramento o un “modello di addestramento” per convalidare dati e può essere utilizzata per generare valori di soglia sul “modello” fake.
ResNet-101: è una rete convoluzionale (CNN) molto profonda, che utilizza una tecnica di skip connection. La ResNet-101 utilizza 101 layers di profondità.
Generative Adversarial Networks (GAN): è l’approccio alla generazione di modelli che utilizza il Deep Learning, come le reti neurali convoluzionali.
Metodi
[ torna al menu ]
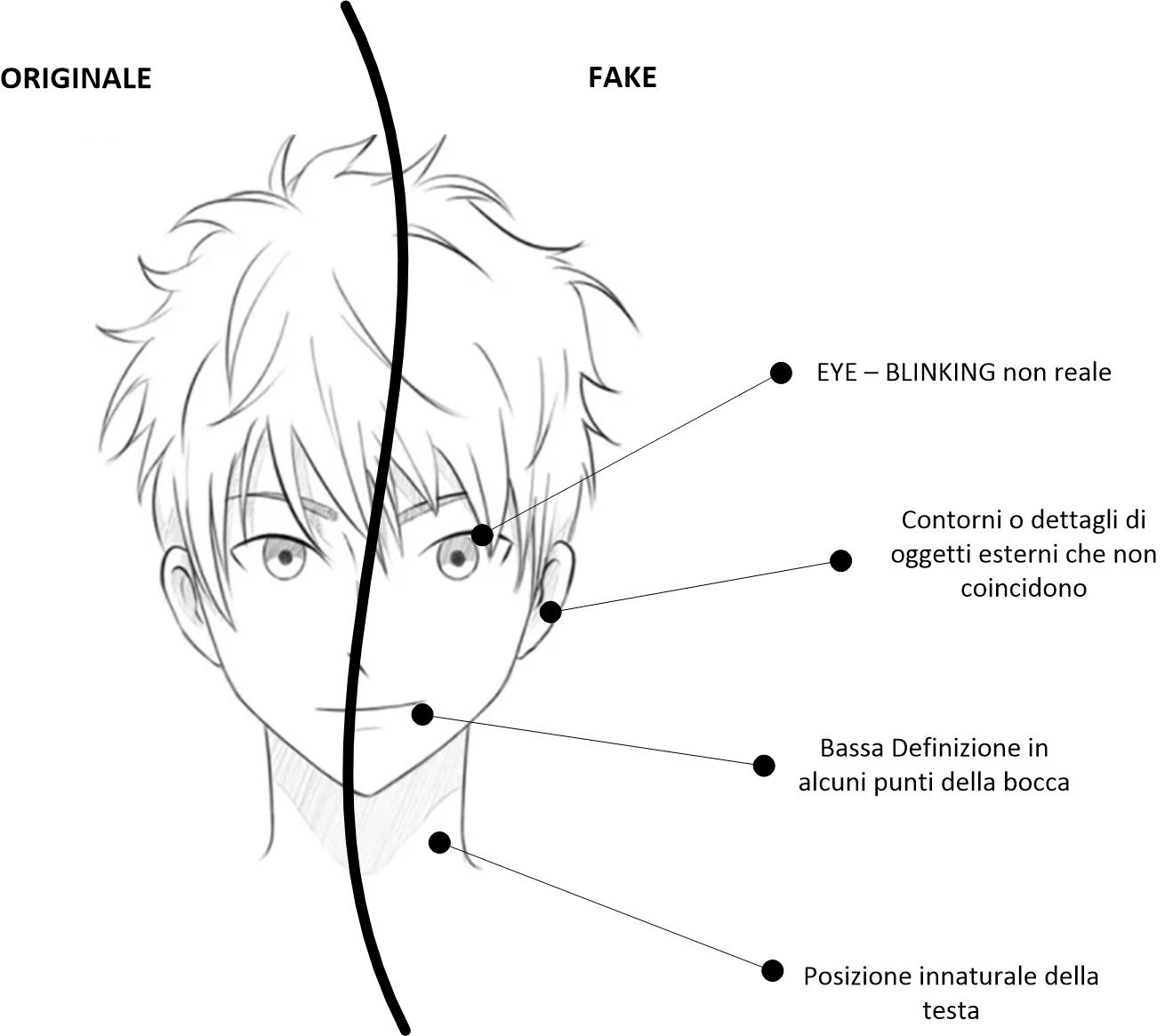
Eye Blinking: viene generato un modello, basato su intelligenza artificiale, che crea un pattern del battito di ciglia del soggetto originale. Il modello viene confrontato con quello del presunto video Fake, che generalmente ha una frequenza del battito di ciglia minore rispetto al video originale.
Intra-Frame ed inconsistenza temporanea: la CNN viene impiegata a livello del frame dell’immagine e distribuita a LSTM per costruire la sequenza finalizzata alla classificazione.
Using face warping artifacts: gli artefatti vengono classificati usando modelli CNN basati sull’inconsistenza della risoluzione tra il viso e l’area circostante ad esso.
MesoNet: è una tecnica sviluppata per il riconoscimento di “deepfake” e “face2swap” basata sul Deep Learning, che sfrutta l’utilizzo di due reti (entrambe con un basso numero di layer per permettere il focus sulle proprietà mesoscopiche dell’immagine) implementando sia un set di dati esistente, sia un set ottenuto da video online.
Capsule-forensics: viene utilizzata la rete VGG-19 che classifica l’immagine attraverso una serie di iterazioni (vero o falso, reale o fake) chiamate “capsule”.
Head-Poses: vengono generati modelli 3D che analizzano una normale “posa” della testa; successivamente viene creato un pattern, poi confrontato con il video. Questa operazione permette di determinare se si tratti di un fake o no.
Eye, teach and facial texture: la rete neurale viene utilizzata per identificare differenze nelle texture del viso, mancanze di riflessi o dettagli nelle zone degli occhi e dei denti.
Spatio-temporal, features with RCN: vengono identificate le discrepanze temporali tra i fotogrammi utilizzando RCN.
Spatio-temporal features with LSTM: una CNN appartenente a XceptionNet viene utilizzata per mappare le caratteristiche del viso.
Analysis of PRNU: viene fatta un’analisi dei disturbi sui sensori delle fotocamere, dovuti a difetti di fabbricazione, successivamente confrontati con quelli dei video potenzialmente fake.
Phoneme-viseme mismatches: poiché i deepfake sintetizzano in maniera errata la chiusura delle labbra, vengono analizzate le discrepanze fra i soggetti relative alla forma della bocca.

Using attribution based confidence (ABC) metric: l’ABC è utilizzata come metrica per identificare un deepfake senza avere accesso al modello di training.
Emotion audiovisual affective cues [143]: per identificare i video fake vengono utilizzati vettori per le emozioni del viso e per le tonalità di voce.
Using appearance and behaviour: approccio basato sulle espressioni biometriche del volto e sui movimenti della testa, sfruttando la rete ResNet101.
FakeCatcher: estrae segni biologici e li usa come descrittori per discriminare i video falsi, poiché i deepfake hanno difficoltà nel riprodurli e mantenerli.
Preprocessing combined with deep network: questa tecnica agisce a più livelli per:
- Migliorare la capacità del Deep Learning sui modelli, per rilevare immagini generate da GAN.
- Rimuovere le funzionalità di basso livello delle immagini false.
- Forzare il Deep Learning a concentrarsi maggiormente sul livello dei pixel e sulla somiglianza tra immagini false e reali.
Defenses against adversarial perturbations in deepfakes: implementando “perturbazioni” per aggirare la loro rilevazione, gli avversari riescono a rendere il riconoscimento dei deepfake più complesso. Questa tecnica migliora la precisione nel rilevare i deepfake utilizzando Lipschitz (in analisi matematica, una funzione che ha una crescita limitata) per la regolazione della profondità dell’immagine.
Analyzing convolutional traces: questa tecnica si concentra nell’identificare deepfake su volti umani con l’obbiettivo di creare un metodo di rilevamento in grado di rintracciare una traccia forense nelle immagini, una sorta di fingerprint del processo di generazione dell’immagine.
Face: Prova ad individuare il confine di fusione tra volti, invece di catturare gli artefatti sintetizzati di specifiche manipolazioni. Può essere addestrato senza immagini false.
Using common artifacts of CNN-generated images: il “classificatore” viene addestrato usando un gran numero di immagini false, in modo da renderlo in grado di riconoscerle.
Quindi, quale modo migliore di affrontare il nemico, utilizzando le sue stesse armi? Il Machine Learning e gli algoritmi di AI devono essere utilizzati per determinare l’autenticità di un “media” digitale. Il lato oscuro è che molti di questi algoritmi, risultano difatti delle “scatole nere” e questo rappresenta un enorme ostacolo, nella quotidianità del loro utilizzo, in quanto ne gli esperti forensi ne tecnici specializzati, riescono ad interpretare correttamente i risultati.


