

Parte I – Intro
Nel dibattito contemporaneo sull’intelligenza artificiale (IA) applicato all’Offensive Security, la questione centrale non è più stabilire se i vari modelli possano contribuire alla vulnerability discovery, ma comprendere in quale misura stiano modificando l’attuale panorama. Attualmente il settore ha raggiunto un punto di inflessione: il processo di discovery mediante IA e, in misura crescente, lo sviluppo di exploit, riduce il tempo disponibile tra identificazione della vulnerabilità, disclosure, remediation e messa in produzione della patch. In altre parole, il ciclo tradizionale discover > disclose > patch > deploy non è stato progettato per un “avversario” che opera a questa velocità.
Il punto non è solo quantitativo. Non si tratta semplicemente di sistemi IA in grado di testare più combinazioni in meno tempo, ma di modelli avanzati che riescono a integrare competenze diverse in un’unica catena operativa: dall’analisi del contesto applicativo alla correlazione di evidenze eterogenee, fino alla comprensione della logica del software e all’elaborazione di percorsi di exploit. Tutte operazioni che, fino a poco tempo fa, richiedevano competenze altamente specialistiche e innumerevoli ore di lavoro umano. Un tale cambiamento riduce drasticamente il tempo di “Initial Access” per le attività offensive: tecniche che un tempo erano appannaggio esclusivo di gruppi molto strutturati stanno diventando sempre più accessibili, economiche e facili da orchestrare.
Per il secondo anno consecutivo, lo sfruttamento delle vulnerabilità nei software esposti su Internet si è confermato il vettore di “Initial Access” a maggior impatto. L’IA, dunque, non crea dal nulla nuove tipologie di minacce, ma piuttosto amplifica dinamiche già esistenti, esasperando il divario tra attacco e difesa. Se da un lato chi attacca trae netto vantaggio dall’automazione, dal parallelismo e dai costi, dall’altro chi difende continua a farsi carico dei tempi e dei costi necessari per validare ogni singola anomalia, testare le correzioni, gestire il rischio residuo e applicare le adeguate contromisure.
Il medesimo set tecnologico che accelera l’offensiva può essere impiegato nella difesa per il testing proattivo, la revisione del codice, l’analisi di componenti terze e lo sviluppo di controlli compensativi o di sistemi di rilevamento più rapidi. Il vero nodo strategico, dunque, non risiede nell’esistenza della tecnologia in sé, ma nella velocità con cui le organizzazioni integrano flussi di lavoro potenziati dall’IA nei propri processi di sicurezza. Chi sceglie di operare ancora secondo i tempi e i modelli decisionali dell’era pre-IA rischia un evidente svantaggio strutturale.
L’articolo che segue si inserisce esattamente in questa cornice. L’obiettivo non è presentare l’IA come un sostituto del penetration tester, né alimentare il mito (almeno per ora) dell’ “hacker-IA”. Al contrario, vorrei mostrare come un primo progetto pilota, basato su ReconFTW, Ollama e un livello di analisi locale, rappresenti un possibile approccio al tema.
In questo scenario, l’IA non funge da “oracolo” o fonte di verità, ma da acceleratore per le fasi di ricognizione, triage, correlazione e reporting. Il valore aggiunto non risiede nell’automazione cieca, ma nella capacità di comprimere i tempi che separano la raccolta dei dati dalla decisione tecnica, garantendo un processo segregato, basato sulle evidenze e sempre sotto il controllo umano.
Parte II – Bootstrap
Prima di buttarci a capofitto nel creare il nostro “agente offensivo” è utile capire cosa faremo:
- Prenderemo un processo di ricognizione “collaudato”
- Lo renderemo ripetibile, utilizzando il sistema operativo Ubuntu
- Ci affiancheremo un modello Large Language Models (LLM) locale
- Costruiremo un layer che interpreta e trasforma i risultati in un report tecnico
Difatti andremo a creare il nostro “agente offensivo locale di supporto”, utilizzando nello specifico i seguenti tool:
Per il processo di ricognizione, utilizzeremo il tool: ReconFTW
| Possiamo immaginare ReconFTW come un drone da ricognizione ad alta tecnologia. Invece di lanciare manualmente innumerevoli strumenti diversi per trovare sottodomini, porte aperte, directory nascoste o vulnerabilità note di un target. ReconFTW esegue automaticamente ognuno di questi tool.
È uno script Bash, che concatena i migliori tool del settore (come Nuclei, dnsx, https, etc…) in un unico flusso di lavoro automatizzato. |
Utilizzeremo Ubuntu come sistema operativo
Il nostro LLM (che girerà in locale) sarà Ollama
| Ollama è un framework open-source che semplifica l’installazione e l’esecuzione di LLM, come Llama 3 o Mistral, direttamente in locale sulle proprie macchine. In ambito IT Security, l’utilizzo di IA pone una seria criticità legata alla Data Confidentiality. Analizzare dump di memoria, log di rete o script proprietari esponendoli a servizi AI basati su cloud (come ChatGPT o Claude) rappresenta un rischio concreto di data leak e potenzialmente una violazione dei Non-Disclosure Agreement (NDA) stipulati con i clienti. |
______________________________________________________________
L’architettura, ridotta all’essenziale, è questa:
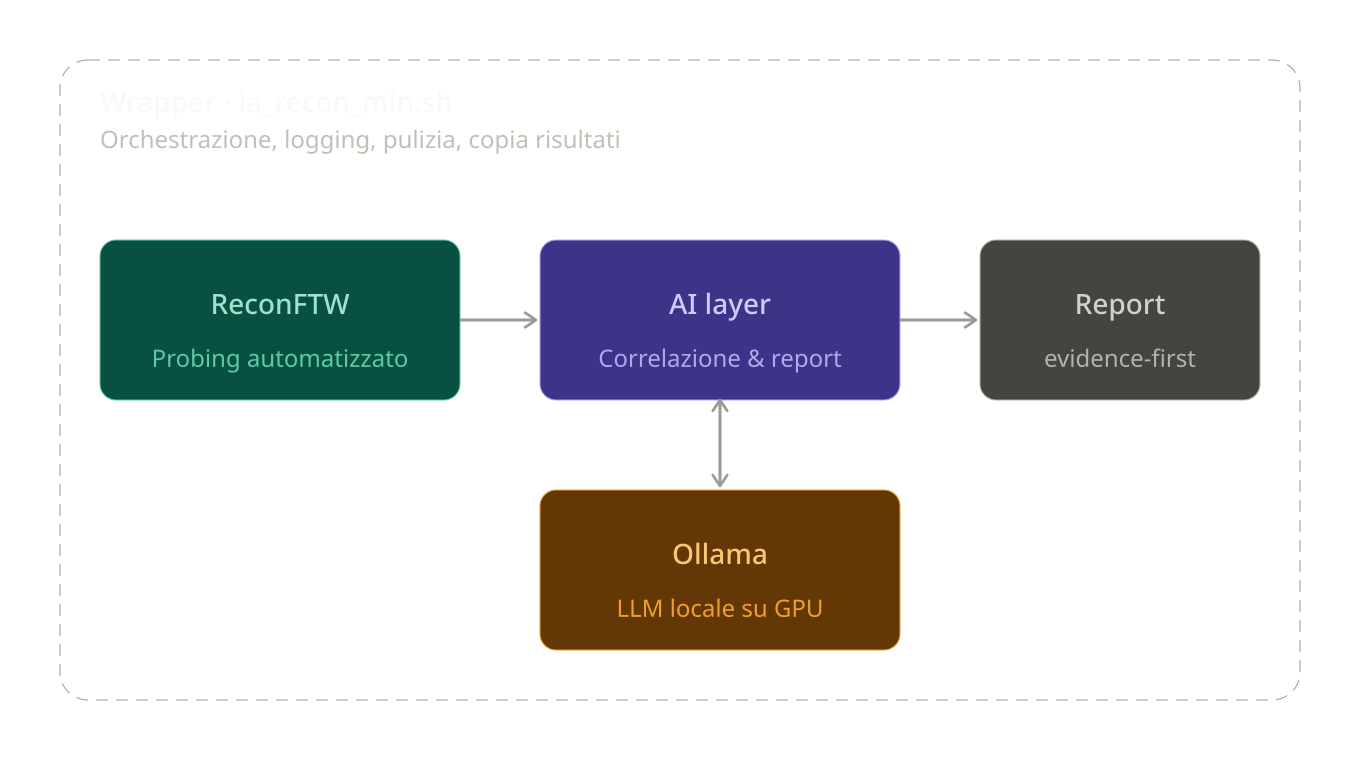
| Nel campo del Machine Learning, l’inferenza è la fase esecutiva in cui un modello elabora una richiesta e genera un risultato. Mentre l’addestramento (training) è il lungo e dispendioso processo in cui l’IA “studia” i dati per costruire la sua rete neurale, l’inferenza è il momento in cui applica ciò che ha imparato per rispondere al nostro prompt, tradurre un testo o, nel nostro caso, analizzare il codice in tempo reale. |
______________________________________________________________
Per questo test utilizzeremo una workstation Ubuntu, con 32 GB di RAM, CPU a 6 core, e una NVIDIA GeForce RTX 2060 con 6 GB di VRAM, con driver NVIDIA Open Kernel Module 580.126.09.
Parte III – Walkthrough
Entriamo adesso nel vivo, e costruiamo il nostro agente offensivo locale da zero, su una workstation Ubuntu con GPU NVIDIA.
La prima cosa da fare è preparare la macchina. Prima di parlare di IA, prompt o riconoscimento della superficie d’attacco, dobbiamo preparare l’ambiente.
Aggiorniamo il sistema:
sudo apt update sudo apt full-upgrade -y sudo reboot
Installiamo adesso il driver NVIDIA raccomandato da Ubuntu:
sudo ubuntu-drivers install sudo reboot
Verifichiamo che la GPU sia vista correttamente dal sistema operativo
nvidia-smi
Il Driver deve essere correttamente inizializzato:
cat /proc/driver/nvidia/version

Ed i moduli del driver NVIDIA per il funzionamento della scheda video (nvidia, nvidia_modeset, nvidia_uvm, nvidia_drm) devono essere caricati e in esecuzione sul sistema:
lsmod | grep nvidia

Se la GPU (Graphics Processing Unit) non è stabile, l’inferenza locale diventa lenta, intermittente o semplicemente ingestibile.
Dopo aver installato le dipendenze è tempo di dedicarci al motore IA locale.
Il cuore del layer IA è Ollama: niente chiamate a provider esterni, niente dati che lasciano la macchina, niente dipendenza da chiavi API o cloud.
Procediamo quindi con l’installazione di Ollama:
curl -fsSL https://ollama.com/install.sh | sh systemctl status ollama --no-pager ollama -v
Scarichiamo il modello locale:
ollama pull llama3:8b
Utilizziamo il comando ollama ls per verificare che il modello sia presente:

Testiamolo con un’inferenza rapida:
ollama run llama3:8b "Scrivi solo OK"

Infine, assicuriamoci che il processo sia stato correttamente caricato in memoria:
ollama ps

Potremmo anche scegliere di continuare a monitorare il processo:
watch -n 1 nvidia-smi
Adesso tocca al nostro “engine” di ricognizione: ReconFTW.
Creiamo una nuova directory e spostiamoci all’interno:
mkdir -p ~/src cd ~/src
Scarichiamo il tool:
git clone https://github.com/six2dez/reconftw
Procediamo all’installazione:
cd reconftw ./install.sh --verbose
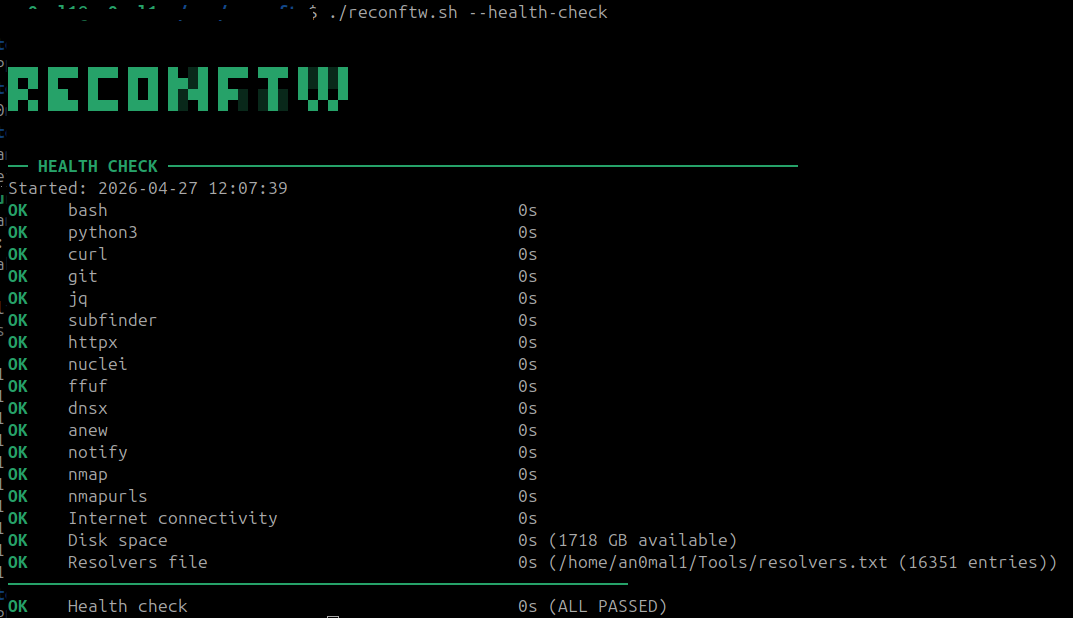
Terminata l’installazione, assicuriamoci che sia anche andata a buon fine:
./reconftw.sh --health-check
| Il file reconftw_ai.py potrebbe generare alcuni falsi positivi, poiché prende le categorie di output e le inietta direttamente nel modello. Il problema nasce quando la nostra ricognizione non produce alcuni dati. Se, ad esempio, mancano le directory osint/, hosts/ o webs/, lo script originale potrebbe leggere questa assenza dati e passarla testualmente all’LLM.
Per risolvere il problema, potremmo voler abbandonare l’approccio standard e creare il nostro wrapper personalizzato. È un passaggio non obbligatorio; nel mio caso utilizzerò un mio wrapper custom, che chiamerò: reconftw_ai_local.py |
| Non è obbligatorio ma potremmo anche decidere di modificare il prompts custom presente di default.
Per farlo, la prima cosa da fare è creare un file di prompt separato da quello originale del progetto. Nel nostro laboratorio, il componente IA risiede nella directory ~/Tools/reconftw_ai/. Qui troviamo già il file prompts.json, usato dal wrapper per costruire i prompt del modello originale. La scelta più corretta, però, è non modificarlo direttamente: un aggiornamento futuro del repository potrebbe sovrascriverlo. Conviene invece duplicarlo in un nuovo file chiamato prompts_custom.json. cd ~/Tools/reconftw_ai cp prompts.json prompts_custom.json nano prompts_custom.json Con il seguente schema concettuale delle regole: {
"rule_1": "Never invent a finding or a file path",
"rule_2": "Only report findings directly supported by supplied data",
"rule_3": "For every finding include exact Evidence / PoC file(s)",
"rule_4": "If evidence is partial, mark it as hypothesis with low confidence"
}
|
A questo punto abbiamo tutti i mattoni sul tavolo: ReconFTW per la ricognizione, Ollama per il modello locale. Adesso dobbiamo mettere assieme le due cose con un launcher: IA_recon_ftw.sh
Creeremo praticamente uno script Bash che orchestra tutte le fasi della pipeline, nell’ordine corretto, senza costringerci a ricordare ogni volta percorsi, flag, file di configurazione, cartelle di output e passaggi intermedi.
Le opzioni che andremo a utilizzare sono tutte native di ReconFTW :
- –health-check: un controllo preliminare (il classico “check motore”) per assicurarsi che tutte le dipendenze e i sub-tool siano installati e funzionanti.
- –dry-run: simula l’esecuzione del comando senza inviare alcun pacchetto reale al target, perfetto per validare la sintassi senza fare rumore.
- -r: avvia una ricognizione completa (Full Recon), ma in modalità “safe”, raccogliendo informazioni senza lanciare attacchi attivi contro l’infrastruttura.
- –adaptive-rate: il nostro “freno a mano” intelligente. Regola dinamicamente la velocità delle richieste per non allarmare i firewall (WAF) ed evitare blocchi o ban (i fastidiosi errori HTTP 429 o 503).
- –no-parallel: esegue i task in sequenza anziché in contemporanea. Allunga leggermente i tempi, ma abbassa drasticamente il carico su CPU e RAM, garantendo la stabilità del sistema.
Creiamo il launcher. Nel mio caso, per comodità lo creerò direttamente sul Desktop, utilizzando sublime (qualsiasi altro editor di testo va bene):
subl ~/Desktop/ia_recon_min.sh
Analizziamo assieme lo script. Mi soffermerò esclusivamente sulle parti più importanti
#!/usr/bin/env bash set -euo pipefail
| In pratica stiamo dicendo a Bash di fermarsi al primo errore serio, di non accettare variabili non definite e di non nascondere gli errori dentro le pipeline. |
export PATH="$HOME/.local/bin:$HOME/go/bin:/usr/local/go/bin:$PATH" # ========================= # Configurazione minima # ========================= SRC="$HOME/src/reconftw" CONFIG_FILE="reconftw.local.cfg" DEFAULT_DEST_ROOT="$HOME/ReconRuns"
| Qui stiamo dicendo allo script dove trovare ReconFTW, quale file di configurazione usare e dove salvare le run. |
# Profilo di scansione scelto per il primo launcher: # full recon senza attacchi attivi, adaptive rate, esecuzione sequenziale. SCAN_ARGS=(-r --adaptive-rate --no-parallel)
| Specifichiamo le opzioni che abbiamo visto all’inizio di questa sezione. |
| La sezione successiva riguarda l’IA, ma con una scelta architetturale molto precisa: la fase IA deve essere opzionale. Se il wrapper locale esiste, viene usato. Se non esiste, lo script prova con reconftw_ai.py. Se nemmeno quello è disponibile, la scansione continua comunque e la fase IA viene saltata. |
# Parametri AI di default
AI_MODEL="llama3:8b"
AI_OUTPUT_FORMAT="md"
AI_REPORT_TYPE="brief"
# Componenti AI opzionali
AI_PY_VENV="$HOME/Tools/reconftw_ai/venv/bin/python3"
AI_SCRIPT_LOCAL="$HOME/Tools/reconftw_ai/reconftw_ai_local.py"
AI_SCRIPT_OFFICIAL="$HOME/Tools/reconftw_ai/reconftw_ai.py"
PROMPTS_CUSTOM="$HOME/Tools/reconftw_ai/prompts_custom.json"
PROMPTS_STOCK="$HOME/Tools/reconftw_ai/prompts.json"
usage() {
echo "Uso: $0 [cartella-output]"
exit 1
}
log() {
printf '%s\n' "$*"
}
die() {
printf '[ERROR] %s\n' "$*" >&2
exit 1
}
TARGET="${1:-}"
DEST_ROOT="${2:-$DEFAULT_DEST_ROOT}"
[[ -n "$TARGET" ]] || usage
[[ -d "$SRC" ]] || die "Directory reconFTW non trovata: $SRC"
[[ -f "$SRC/reconftw.sh" ]] || die "File non trovato: $SRC/reconftw.sh"
[[ -f "$SRC/$CONFIG_FILE" ]] || die "File di configurazione non trovato: $SRC/$CONFIG_FILE"
# =========================
# Selezione layer AI
# =========================
AI_ENABLED="yes"
AI_PY="python3"
if [[ -x "$AI_PY_VENV" ]]; then
AI_PY="$AI_PY_VENV"
fi
if [[ -f "$AI_SCRIPT_LOCAL" ]]; then
AI_SCRIPT="$AI_SCRIPT_LOCAL"
elif [[ -f "$AI_SCRIPT_OFFICIAL" ]]; then
AI_SCRIPT="$AI_SCRIPT_OFFICIAL"
else
AI_ENABLED="no"
fi
if [[ "$AI_ENABLED" == "yes" ]]; then
if [[ -f "$PROMPTS_CUSTOM" ]]; then
PROMPTS_FILE="$PROMPTS_CUSTOM"
elif [[ -f "$PROMPTS_STOCK" ]]; then
PROMPTS_FILE="$PROMPTS_STOCK"
else
AI_ENABLED="no"
fi
fi
if [[ "$AI_ENABLED" == "yes" ]]; then
if ! python3 -m json.tool "$PROMPTS_FILE" >/dev/null 2>&1; then
echo "[!] File prompt non valido: salto la fase AI"
AI_ENABLED="no"
fi
fi
# =========================
# Cartelle di output
# =========================
RUNSTAMP="$(date +%F_%H%M%S)"
BASE="$DEST_ROOT/$TARGET/$RUNSTAMP"
RAW="$BASE/recon_raw"
AI="$BASE/ai_report"
LOGS="$BASE/logs"
mkdir -p "$RAW" "$AI" "$LOGS"
touch "$BASE/.write_test" && rm -f "$BASE/.write_test"
if command -v stdbuf >/dev/null 2>&1; then
STDBUF=(stdbuf -oL -eL)
else
STDBUF=()
fi
# =========================
# Esecuzione
# =========================
cd "$SRC"
log "[*] Health check..."
./reconftw.sh --health-check | tee "$LOGS/health.log"
log "[*] Dry-run..."
"${STDBUF[@]}" ./reconftw.sh -d "$TARGET" "${SCAN_ARGS[@]}" -f "$CONFIG_FILE" --dry-run \
2>&1 | tee "$LOGS/recon_dryrun.log"
read -r -p "Premi INVIO per lanciare la run reale oppure Ctrl+C per annullare... " _
# Pulizia della working directory interna per evitare cache e artefatti vecchi
rm -rf "$SRC/Recon/$TARGET"
log "[*] Scan reale..."
"${STDBUF[@]}" ./reconftw.sh -d "$TARGET" "${SCAN_ARGS[@]}" -f "$CONFIG_FILE" \
2>&1 | tee "$LOGS/recon.log"
[[ -d "$SRC/Recon/$TARGET" ]] || die "Cartella risultati interna non trovata"
cp -a "$SRC/Recon/$TARGET/." "$RAW/"
if [[ "$AI_ENABLED" == "yes" ]]; then
log "[*] Analisi AI..."
if ! "$AI_PY" "$AI_SCRIPT" \
--results-dir "$RAW" \
--output-dir "$AI" \
--model "$AI_MODEL" \
--output-format "$AI_OUTPUT_FORMAT" \
--report-type "$AI_REPORT_TYPE" \
--prompts-file "$PROMPTS_FILE" \
2>&1 | tee "$LOGS/ai.log"
then
echo "[!] Analisi AI fallita. I risultati raw restano comunque salvati."
fi
else
echo "[*] Fase AI saltata: wrapper o prompt non disponibili."
fi
echo
echo "Run completata."
echo "Output base : $BASE"
echo "Recon raw : $RAW"
echo "AI report : $AI"
echo "Logs : $LOGS"
find "$BASE" -maxdepth 2 -type f | sort || true
Non ci resta adesso che rendere eseguibile lo script. Facciamo solo un rapido check sulla sintassi bash.
bash -n ~/Desktop/ia_recon_min.sh
Se il comando non restituisce output, la sintassi è corretta.
Il secondo passaggio è rendere il file eseguibile:
chmod +x ~/Desktop/ia_recon_min.sh
A questo punto il launcher è pronto.
Non ci resta che eseguilo. Al termine della scansione otterremo un output simile:
Parte IV – Conclusioni
Il progetto descritto in questo articolo non vuole dimostrare l’esistenza di un fantomatico “hacker-IA” autonomo. Vuole mostrare qualcosa di più utile: come prendere una pipeline di ricognizione collaudata, affiancarle un modello locale e ottenere un livello di analisi più rapido, più leggibile e più controllabile. I singoli componenti non sono nuovi; il valore sta nel modo in cui vengono orchestrati.
Un penetration tester può costruirsi un agente offensivo capace di risparmiare tempo, ordinare meglio le evidenze e restituire valore operativo reale.
A mio avviso, è proprio da qui che conviene partire.
AI-Assisted Reconnaissance & Triage — Active Scanning / Gather Victim Network Information (T1595 / T1590): utilizzo di una pipeline di ricognizione automatizzata, affiancata da un modello LLM locale, per raccogliere, normalizzare e correlare informazioni tecniche su domini, host, servizi esposti, tecnologie e possibili superfici vulnerabili. In questo scenario l’IA non esegue direttamente l’attacco, ma accelera triage, prioritizzazione e reporting delle evidenze prodotte da strumenti come ReconFTW. La tecnica si colloca principalmente nella fase di Reconnaissance, con riferimenti a Active Scanning (T1595), Vulnerability Scanning (T1595.002) e Gather Victim Network Information (T1590)


